这个插件对于 ComfyUI 用户来说,实用性非常高,而且考虑到了不同的硬件配置需求。
技术整合很到位:它直接把像 Qwen3-VL 这样领先的视觉语言模型带到了 ComfyUI 的节点式工作流中,让用户能以更直观的方式使用多模态能力,无论是图片分析还是未来的视频处理(根据介绍),都提供了强大的基础。它不仅追赶最新的 Qwen3-VL 模型,还保持对早期 Qwen2.5 的支持,这让拥有不同模型的用户都能受益。最值得称赞的是它加入了多种量化(4-bit/8-bit)和模型缓存的选项。这意味着开发者清晰地认识到 VRAM 是限制许多 AI 玩家的主要瓶颈,通过这些优化,可以让更多配置没那么“壕”的用户也能体验到高性能 VL 模型,这大大提升了它的普及潜力。
总体来看,这是一个强大、灵活且注重实用的节点集,为 ComfyUI 的多模态能力添加了重要的一块拼图。
节点官方介绍:
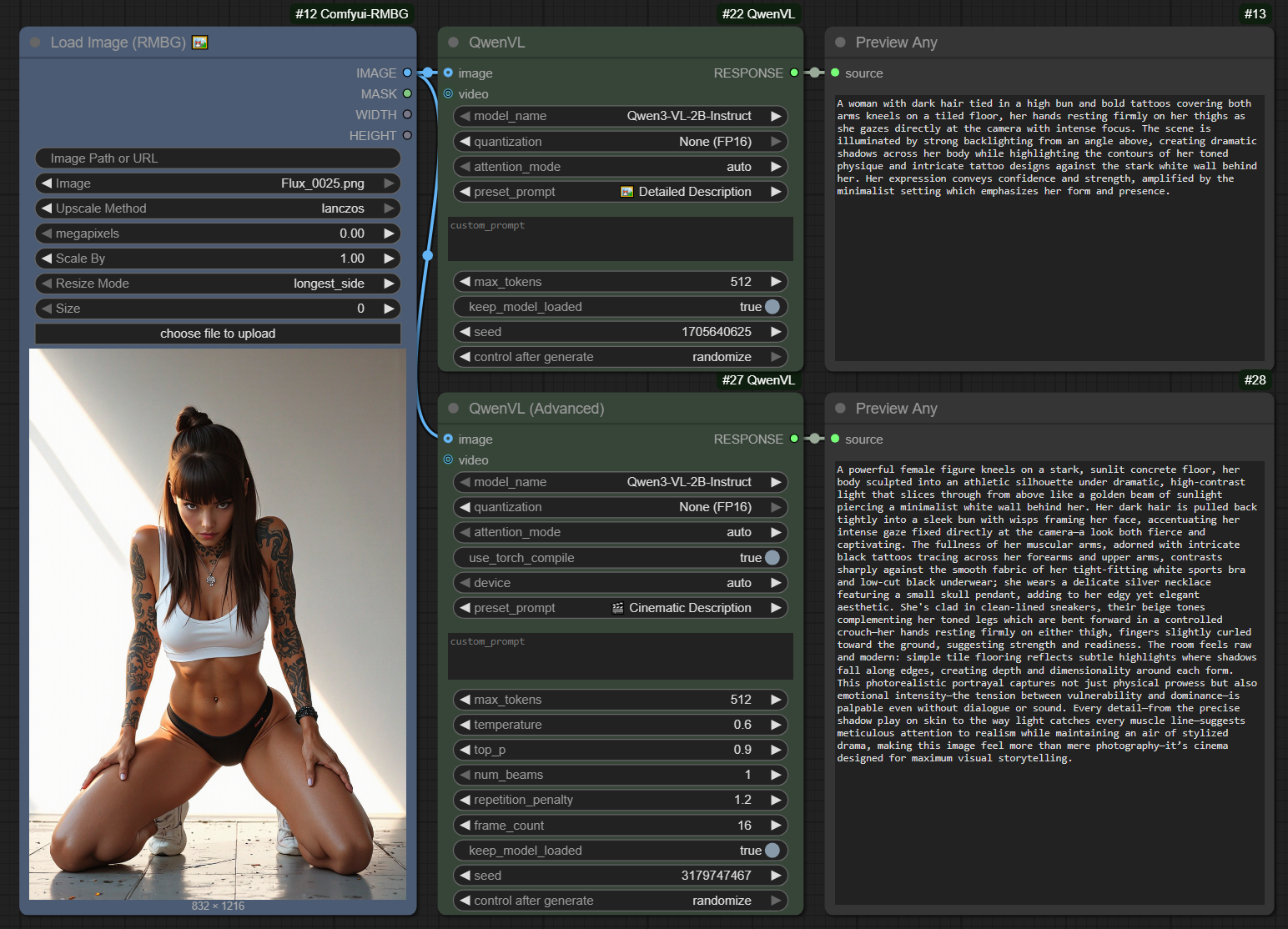
ComfyUI-QwenVL 自定义节点集成了 Qwen-VL 系列,包括最新的 Qwen3-VL 型号,以及 Qwen2.5-VL 和最新的 Qwen3-VL,从而实现了用于生成文本、图像理解和视频分析的高级多模态 AI。
开源地址:https://github.com/1038lab/ComfyUI-QwenVL
ComfyUI-QwenVL 自定义节点集成了阿里云强大的 Qwen-VL 系列视觉语言模型 (LVLM),包括最新的 Qwen3-VL 和 Qwen2.5-VL。该高级节点可在 ComfyUI 工作流程中实现无缝的多模态 AI 功能,从而高效地生成文本、理解图像和分析视频。
✨ 特点
- 标准节点和高级节点:包含一个用于快速使用的简单 QwenVL 节点和一个可对生成进行精细控制的 QwenVL(高级)节点。
- 预设和自定义提示:您可以从一系列便捷的预设提示中进行选择,也可以编写自己的提示以实现完全控制。
- 多型号支持:轻松切换各种官方 Qwen-VL 型号。
- 自动模型下载:模型会在首次使用时自动下载。
- 智能量化:通过 4 位、8 位和 FP16 选项平衡 VRAM 和性能。
- 硬件感知:自动检测 GPU 功能,防止与不兼容的型号(例如 FP8)发生错误。
- 可复现生成:使用种子参数以获得一致的输出。
- 内存管理:“保持模型加载”选项可将模型保留在 VRAM 中,以加快处理速度。
- 图像和视频支持:接受单个图像和视频帧序列作为输入。
- 强大的错误处理能力:针对硬件或内存问题提供清晰的错误消息。
- 简洁的控制台输出:运行期间输出简洁明了的控制台日志。Flash -Attention v2 集成:可用时自动启用,以加快注意力层速度。Torch 编译优化:可选的 JIT 编译,
use_torch_compile以提高吞吐量。 高级设备处理:自动检测 CUDA、Apple Silicon (MPS) 或 CPU;可手动覆盖。 动态内存强制执行:根据 VRAM 可用性自动调整量化级别。
🚀 安装
- 将此仓库克隆到您的 ComfyUI/custom_nodes 目录:
cd ComfyUI/custom\_nodes git clone https://github.com/1038lab/ComfyUI-QwenVL.git - 安装所需的依赖项:
cd ComfyUI/custom_nodes/ComfyUI-QwenVL pip install -r requirements.txt - 重启ComfyUI。
📥 下载模型
首次使用时,模型将自动下载。如果您希望手动下载,请将其放置在 ComfyUI/models/LLM/Qwen-VL/ 目录中。
| 模型 | 关联 |
|---|---|
| Qwen3-VL-2B-指令 | 下载 |
| Qwen3-VL-2B-思考 | 下载 |
| Qwen3-VL-2B-指令-FP8 | 下载 |
| Qwen3-VL-2B-思考-FP8 | 下载 |
| Qwen3-VL-4B-指令 | 下载 |
| Qwen3-VL-4B-思考 | 下载 |
| Qwen3-VL-4B-指令-FP8 | 下载 |
| Qwen3-VL-4B-思考-FP8 | 下载 |
| Qwen3-VL-8B-指令 | 下载 |
| Qwen3-VL-8B-思考 | 下载 |
| Qwen3-VL-8B-指令-FP8 | 下载 |
| Qwen3-VL-8B-思考-FP8 | 下载 |
| Qwen3-VL-32B-指令 | 下载 |
| Qwen3-VL-32B-思考 | 下载 |
| Qwen3-VL-32B-指令-FP8 | 下载 |
| Qwen3-VL-32B-思考-FP8 | 下载 |
| Qwen2.5-VL-3B-指令 | 下载 |
| Qwen2.5-VL-7B-指令 | 下载 |
📖 用法
基本用法
- 从 🧪AILab/QwenVL 类别中添加“QwenVL”节点。
- 选择您要使用的模型名称。
- 将图像或视频(图像序列)源连接到节点。
- 您可以使用预设字段或自定义字段编写提示信息。
- 运行工作流程。
高级用法
如需更精细的控制,请使用“QwenVL(高级)”节点。该节点可让您访问详细的生成参数,例如温度、top_p、光束搜索和器件选择。
⚙️ 参数
| 范围 | 描述 | 默认 | 范围 | 节点 |
|---|---|---|---|---|
| 模型名称 | 要使用的Qwen-VL模型。 | Qwen3-VL-4B-指令 | – | 标准版和高级版 |
| 量化 | 即时量化。对于预量化模型(例如 FP8),此操作将被忽略。 | 8 位(平衡) | 4 位、8 位、无 | 标准版和高级版 |
| 注意模式 | 注意后端。auto如果可用,则尝试使用 Flash-Attn v2,否则回退到 SDPA。 | 汽车 | 自动、闪光灯_注意_2、SDPA | 标准版和高级版 |
| 使用 torch 编译 | 启用torch.compile('reduce-overhead')以提高 CUDA 吞吐量(Torch 2.1+)。 | 假 | – | 仅限高级用户 |
| 设备 | 取消自动设备选择。 | 汽车 | 自动、CUDA、CPU | 仅限高级用户 |
| 预设提示 | 针对常见任务的一系列预定义提示。 | 请描述一下…… | 任何文本 | 标准版和高级版 |
| 自定义提示 | 如果提供了预设提示,则覆盖该提示。 | 任何文本 | 标准版和高级版 | |
| 最大令牌数 | 要生成的新代币的最大数量。 | 1024 | 64-2048 | 标准版和高级版 |
| 保持模型加载 | 将模型保存在显存中,以便后续运行速度更快。 | 真的 | 真/假 | 标准版和高级版 |
| 种子 | 可重复结果的种子。 | 1 | 1 – 2^64-1 | 标准版和高级版 |
| 温度 | 控制随机性。数值越高,随机性越强。(当 num_beams 为 1 时使用)。 | 0.6 | 0.1-1.0 | 仅限高级用户 |
| 顶部_p | 细胞核采样阈值。(当 num_beams 为 1 时使用)。 | 0.9 | 0.0-1.0 | 仅限高级用户 |
| 光束数 | 用于光束搜索的光束数量。大于 1 则禁用温度/top_p 采样。 | 1 | 1-10 | 仅限高级用户 |
| 重复惩罚 | 不鼓励重复使用令牌。 | 1.2 | 0.0-2.0 | 仅限高级用户 |
| 帧数 | 要从视频输入中采样的帧数。 | 16 | 1-64 | 仅限高级用户 |
💡 量化选项
| 模式 | 精确 | 内存使用情况 | 速度 | 质量 | 推荐用于 |
|---|---|---|---|---|---|
| 无(FP16) | 16 位浮点数 | 高的 | 最快 | 最好的 | 高显存显卡(16GB+) |
| 8 位(平衡) | 8位整数 | 中等的 | 快速地 | 非常好 | 均衡性能(8GB+) |
| 4 位(对显存友好) | 4位整数 | 低的 | 慢点* | 好的 | 低显存显卡(<8GB) |
*关于 4 位速度的说明:4 位量化可以显著降低 VRAM 使用量,但由于实时反量化的计算开销,可能会导致某些系统的性能变慢。
🤔 设置技巧
| 环境 | 推荐 |
|---|---|
| 模型选择 | 对于大多数用户来说,Qwen3-VL-4B-Instruct 是一个很好的起点。如果您使用的是 40 系列 GPU,请尝试使用 -FP8 版本以获得更好的性能。 |
| 内存模式 | 如果您计划多次运行该节点,请保持 keep_model_loaded 启用(True)以获得最佳性能。仅当其他节点的显存不足时才禁用它。 |
| 量子化 | 首先使用默认的 8 位模式。如果显存充足(>16GB),请切换到“无”(FP16)模式以获得最佳速度和质量。如果显存不足,请使用 4 位模式。 |
| 表现 | 首次使用特定量化方式加载模型时,速度可能会较慢。后续运行(启用 keep_model_loaded 参数)速度会快得多。 |
🧠 关于模型
该节点采用阿里云Qwen团队开发的Qwen-VL系列模型。这些强大的开源大型视觉语言模型(LVLM)旨在理解和处理视觉和文本信息,因此非常适合图像和视频详细描述等任务。