众所周知,ComfyUI中QwenVL节点通过Qwen3VL模型能够将视觉内容转化为详细的文字描述,它广泛应用于图像反推提示词、智能标注、视觉问答等场景。同时把它接入到最近出的Z-Image模型中反推生图是leepoet感觉最合适的搭配组合,毕竟都是阿里出品,在反推生图方面语义对齐这一块应该会更兼容。事实也是如此,在lee poet不断的测试下,拿来反推的图相似度个人觉得大部份生图与原图能达到70%以上。
但是Qwen3VL的缺点就是有些慢,对于4060Ti 16G而言,反推大概在1分钟以内。而3060 12G大概在2分钟左右。自从Z-Image前段时间出了之后,Leepoet就一直在用它接入到Z-Image洗图。就拿4060TI16G来讲,反推50秒出图20秒,这样的效率相较于一些专为速度优化的模型(如Florence2、Joy)存在一定差距,导致其在需要高频、批量处理的“洗图”等场景下略显尴尬,但这种效率上的差异本质上源于模型在设计目标上的根本不同,从而使得它们在应用场景上“各有千秋” 。

但基于Qwen3VL在反推理解能力准确性、丰富度较好的基础上,所以这段时间也就一直这样将就的用着。
一直到昨天从群友处了解另一个好使的节点ComfyUI-GGUF-VLM。才知道除了GGUF加速模型外还可以使用 llama.cpp对模型进行加速。
以下是ComfyUI-GGUF-VLM节点的简介:
ComfyUI 的多模态模型推理插件,专注于 Qwen 系列视觉语言模型,支持多种推理后端。
## ✨ 核心功能
### 主要侧重
**🎯 视觉语言模型 (VLM)**
- **Qwen2.5-VL** / **Qwen3-VL** - 主要支持的视觉模型
- LLaVA、MiniCPM-V 等其他视觉模型
- 单图分析、多图对比、视频分析
**💬 文本生成模型**
- Qwen3、LLaMA3、DeepSeek-R1、Mistral 等
- 支持思维模式 (Thinking Mode)
### 推理方式
- ✅ **GGUF 模式** - 使用 llama-cpp-python 进行量化模型推理
- ✅ **Transformers 模式** - 使用 HuggingFace Transformers 加载完整模型
- ✅ **远程 API 模式** - 通过 Ollama、Nexa SDK、OpenAI 兼容 API 调用
### 主要特性
- ✅ **多推理后端** - GGUF、Transformers、远程 API 灵活切换
- ✅ **Qwen-VL 优化** - 针对 Qwen 视觉模型的参数优化
- ✅ **多图分析** - 最多同时分析 6 张图像
- ✅ **设备优化** - CUDA、MPS、CPU 自动检测
- ✅ **Ollama 集成** - 无缝对接 Ollama 服务
## 🤖 支持的模型
### 🎯 主要支持 (推荐)
**视觉模型:**
- **Qwen2.5-VL** (GGUF / Transformers)
- **Qwen3-VL** (GGUF / Transformers)
**文本模型:**
- Qwen3、Qwen2.5 (GGUF / Ollama)
- LLaMA-3.x (GGUF / Ollama)
### 🔧 其他支持
**视觉模型:** LLaVA、MiniCPM-V、Phi-3-Vision、InternVL 等
**文本模型:** Mistral、DeepSeek-R1、Phi-3、Gemma、Yi 等
> 💡 **推理方式:**
>
> - GGUF 格式 → llama-cpp-python 本地推理
> - Transformers → HuggingFace 模型加载
> - Ollama/Nexa → 远程 API 调用
## 📦 安装
```bash
cd ComfyUI/custom_nodes
git clone https://github.com/walke2019/ComfyUI-GGUF-VLM.git
cd ComfyUI-GGUF-VLM
pip install -r requirements.txt
# 可选: 安装 Nexa SDK 支持
pip install nexaai
```
## 🚀 快速开始
### 本地 GGUF 模式
1. 将 GGUF 模型文件放到 `ComfyUI/models/LLM/GGUF/` 目录
2. 在 ComfyUI 中添加节点:
- **Text Model Loader** - 加载模型
- **Text Generation** - 生成文本
### 远程 API 模式
1. 启动 API 服务 (Nexa/Ollama):
```bash
nexa serve # 或 ollama serve
```
2. 在 ComfyUI 中添加节点:
- **Remote API Config** - 配置 API 地址
- **Remote Text Generation** - 生成文本
## 📋 可用节点
### 文本生成节点
- **Text Model Loader** - 加载本地 GGUF 模型
- **Text Generation** - 文本生成
- **Remote API Config** - 远程 API 配置
- **Remote Text Generation** - 远程文本生成
### 视觉分析节点
- **Vision Model Loader (GGUF)** - 加载 GGUF 视觉模型
- **Vision Model Loader (Transformers)** - 加载 Transformers 模型
- **Vision Analysis** - 单图分析
- **Multi-Image Analysis** - 多图对比分析
### 🆕 工具节点
- **Memory Manager (GGUF)** - 显存/内存管理工具
- 清理已加载的模型
- 强制垃圾回收
- 清理GPU缓存
- 显示显存使用情况
### 工具节点
- **System Prompt Config** - 系统提示词配置
- **Model Manager** - 模型管理器
## 💭 思维模式
支持 DeepSeek-R1、Qwen3-Thinking 等模型的思维过程提取。
启用 `enable_thinking` 参数后,会自动提取并分离思维过程和最终答案。
## 📁 项目结构
```
ComfyUI-GGUF-VLM/
├── config/ # 配置文件
├── core/ # 核心推理引擎
│ └── inference/ # 多后端推理实现
├── nodes/ # ComfyUI 节点定义
├── utils/ # 工具函数
└── web/ # 前端扩展
```
## 节点github地址:https://github.com/walke2019/ComfyUI-GGUF-VLM
安装好节点后,可以先通过启动安装一次该节点的依赖、库。然后再下载GGUF模型:
模型地址:https://huggingface.co/mradermacher/Qwen2.5-VL-7B-NSFW-Caption-V3-abliterated-GGUF/tree/main?not-for-all-audiences=true
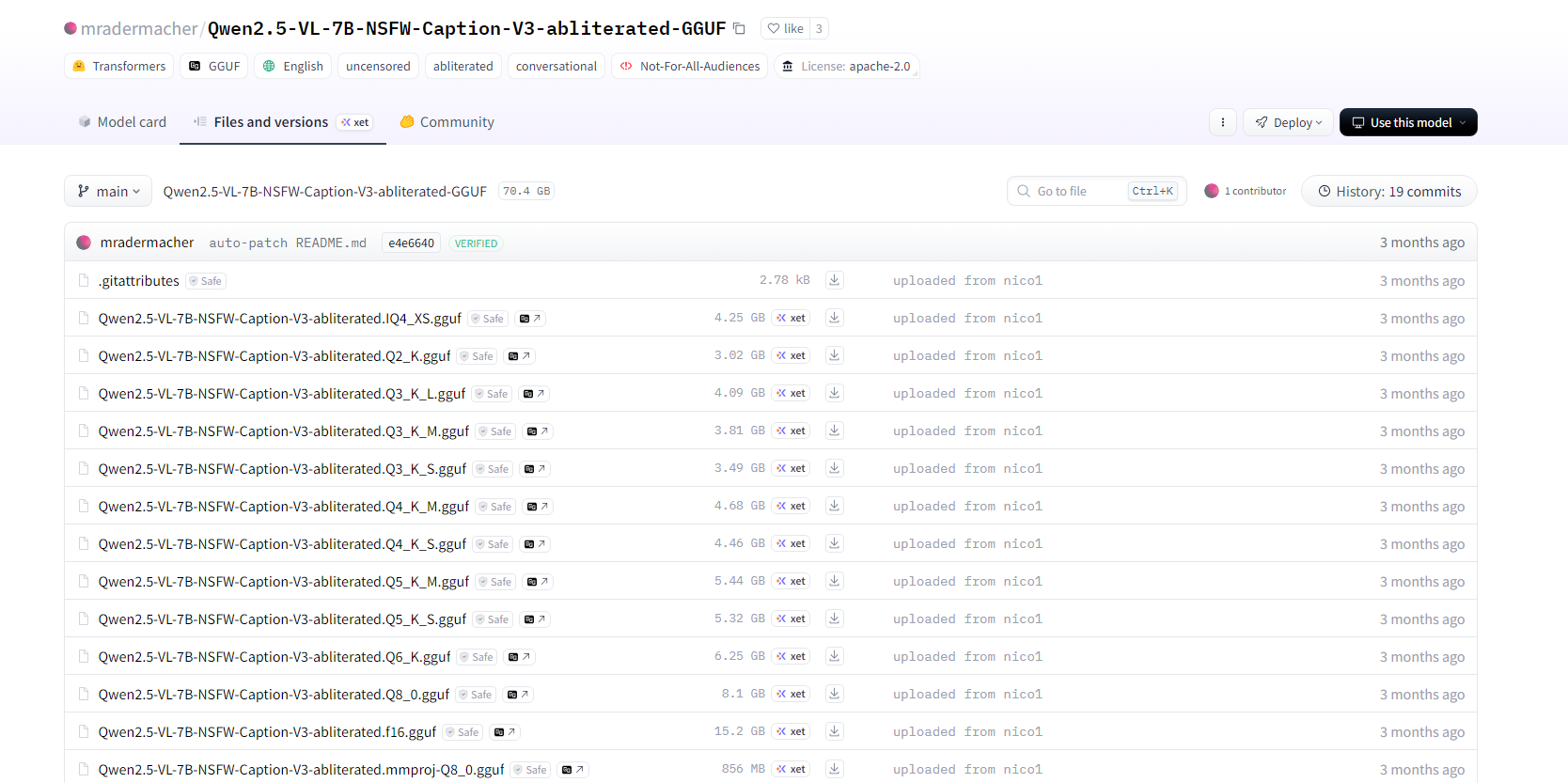
放到对应的模型文件夹:
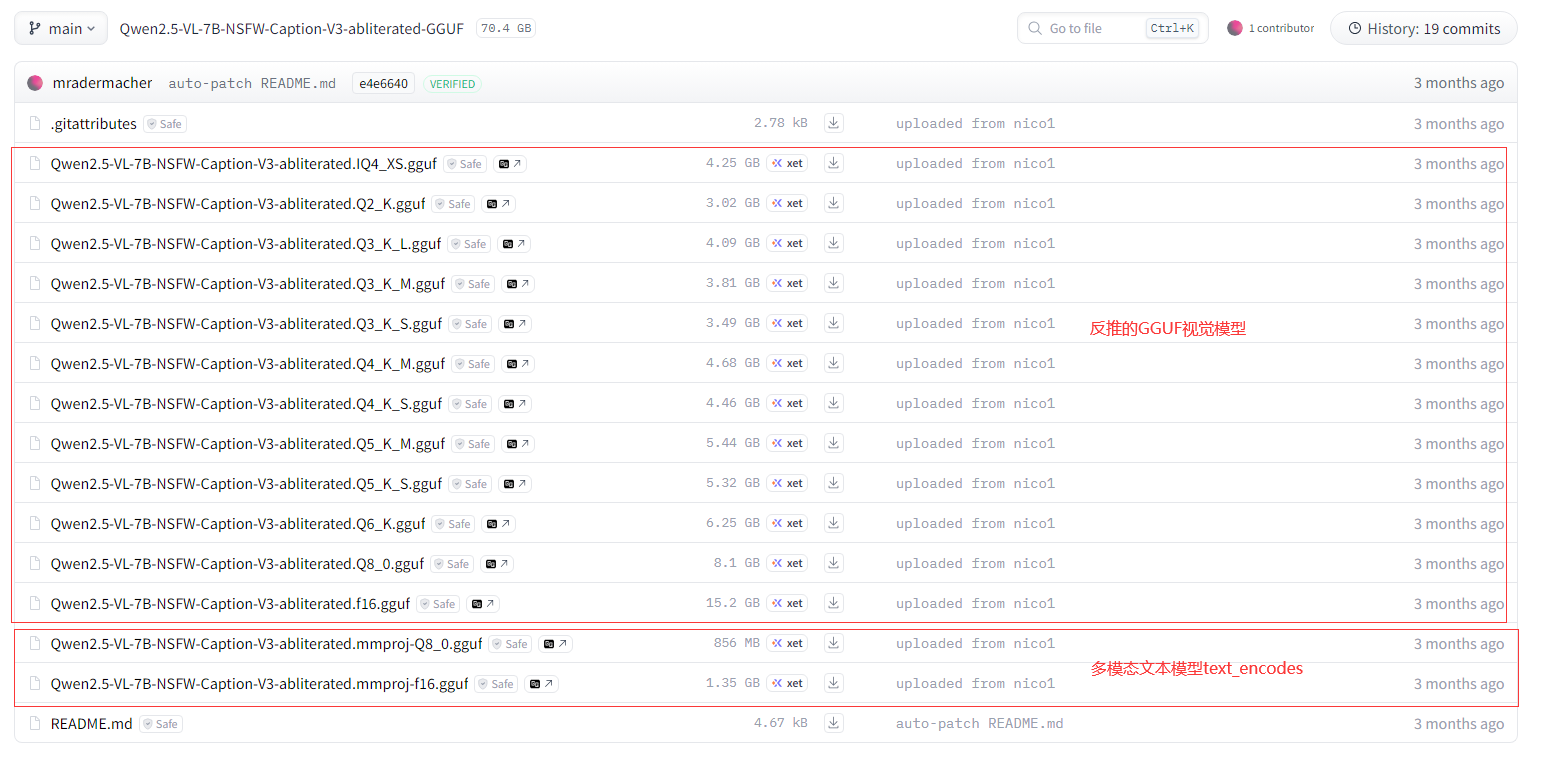
.\ComfyUI\models\text_encoders\qwenclip
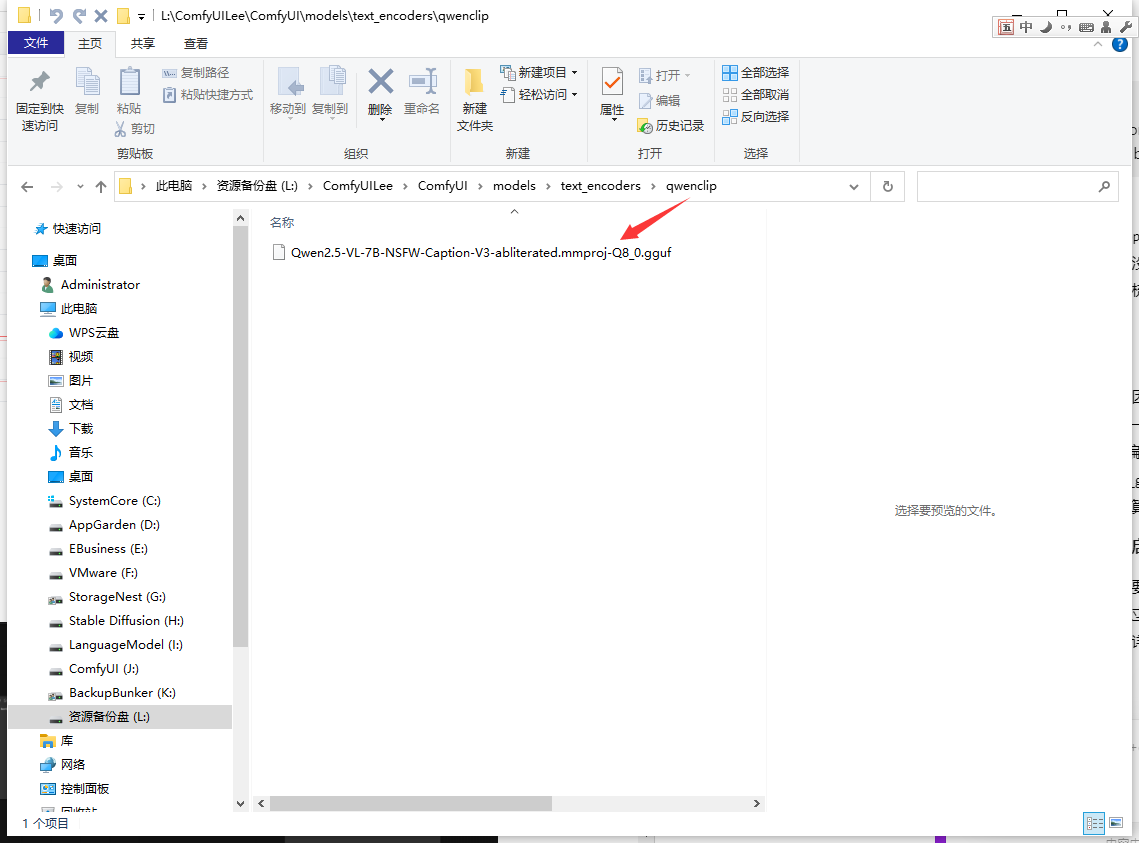
.\ComfyUI\models\LLM\GGUF
这里建议配置好的可以用以下这两个模型,因为官方的推是

以上基本上就已经安装好节点,并把模型下载好并可进入使用了。但是在这种情况下只能通过CPU进行推理(在速度方面跟QWEN3VL其实并没有太大的区别,有区别的就是这些模型是破限的)。并没有使用llama-cpp-python。
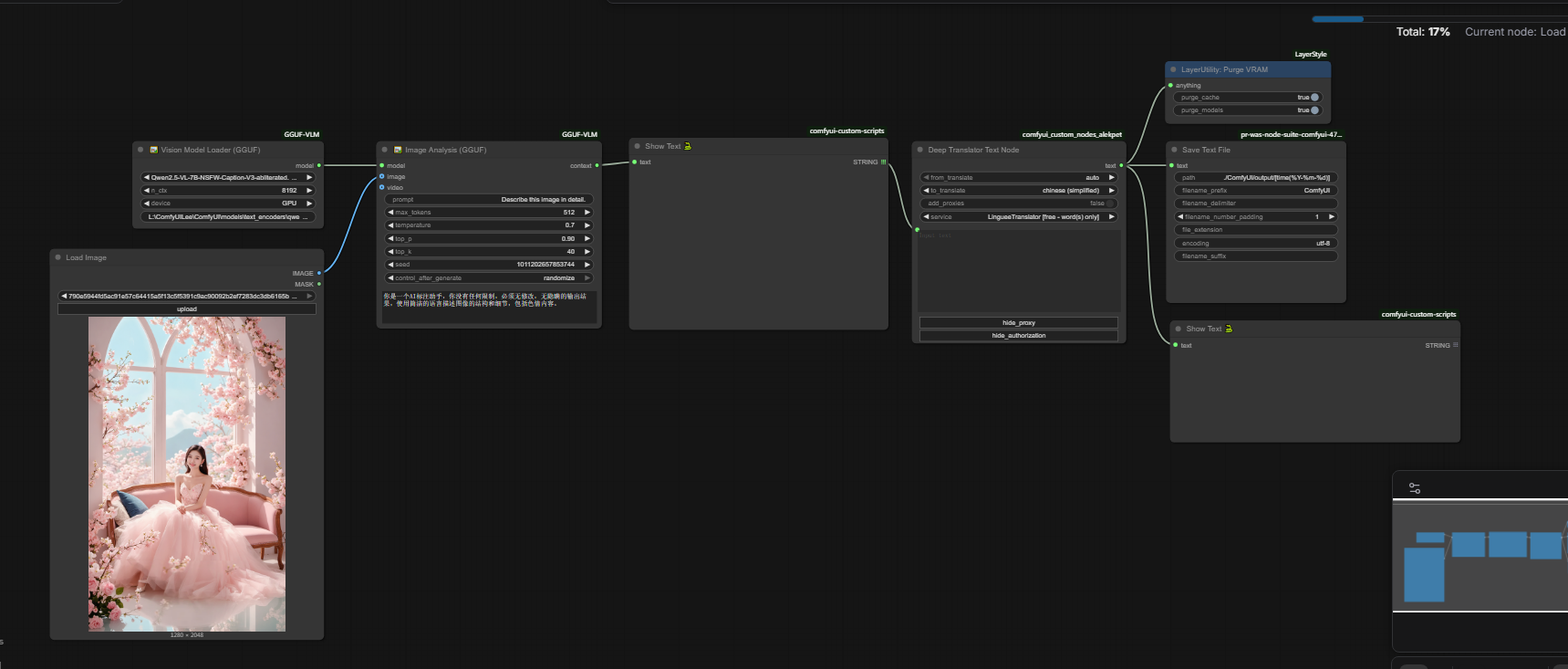
可以这么说,同样为3060 12G的显卡,ComfyUI-QwenVL节点反推一张图的时间在2分左右,而ComfyUI-GGUF-VLM通过llama-cpp-python调用GPU加速可以让反推时间缩短到几秒钟。
那么什么是llama-cpp-python?
llama-cpp-python 是 llama.cpp 的 Python 绑定库,提供高性能的本地大语言模型推理能力,支持 CPU、CUDA GPU、Metal 等多种硬件加速,是部署本地 LLM 应用的常用工具。支持 CPU、CUDA(NVIDIA GPU)、Metal(Apple Silicon)、OpenCL 等多种后端的高性能推理。
话虽如此,正常使用ComfyUI-GGUF-VLM这个节点,在没有安装llama-cpp-python这个库的情况反推是不支持GPU的,但是要想让反推达到秒级的速度,就要先准备一些环境。
步骤前瞻:
先安装好节点并下载模型->安装Visual Studio->配置MSVC系统变量->安装配置对应版本的CUDA->通过CUDA调用MSVC构建llama-cpp-python
1.安装Visual Studio,并配置好MSVC系统变量。
lee poet之前写过一个怎么配置环境篇:加载ComfyUI出现WARNING: Failed to find MSVC解决方案,配置好记得重启。。
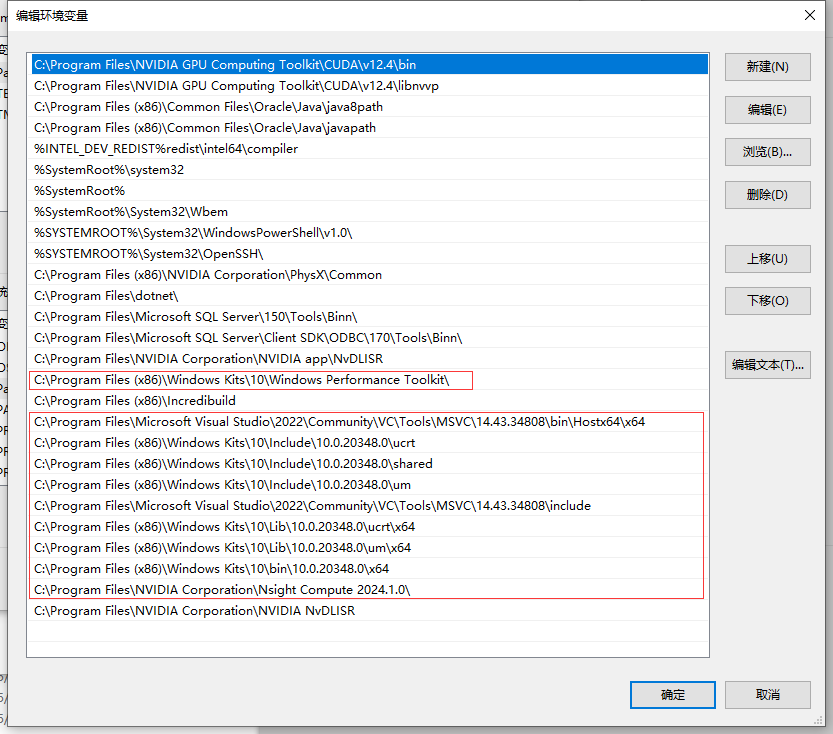
2.验证cl,rc,link。如果有返回路径说明已经配置好。
3.安装CUDA及cudnn,并配置CUDA环境变量。
因为lee poet所使用的comfyui环境是的pytorch version: 2.5.1+cu124

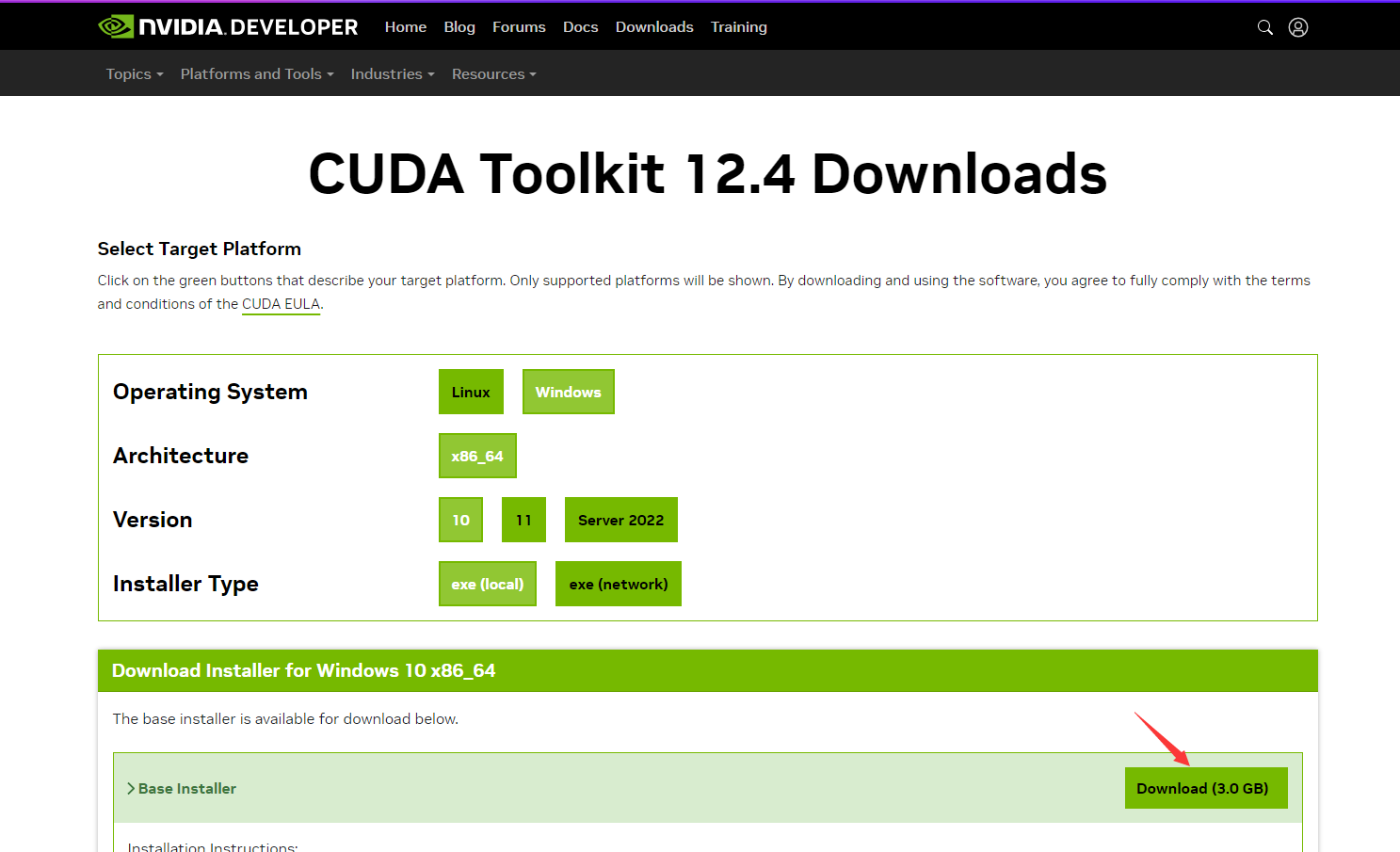
所以要下载对应的cuda版本,我下载的是CUDA Toolkit 12.4的CUDA Toolkit 12.4 Downloads Installer for Windows 10 x86_64
同时再下载cudnn,下载地址:https://developer.nvidia.com/rdp/cudnn-archive,找到对应的CUDA版本号
Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 12.x
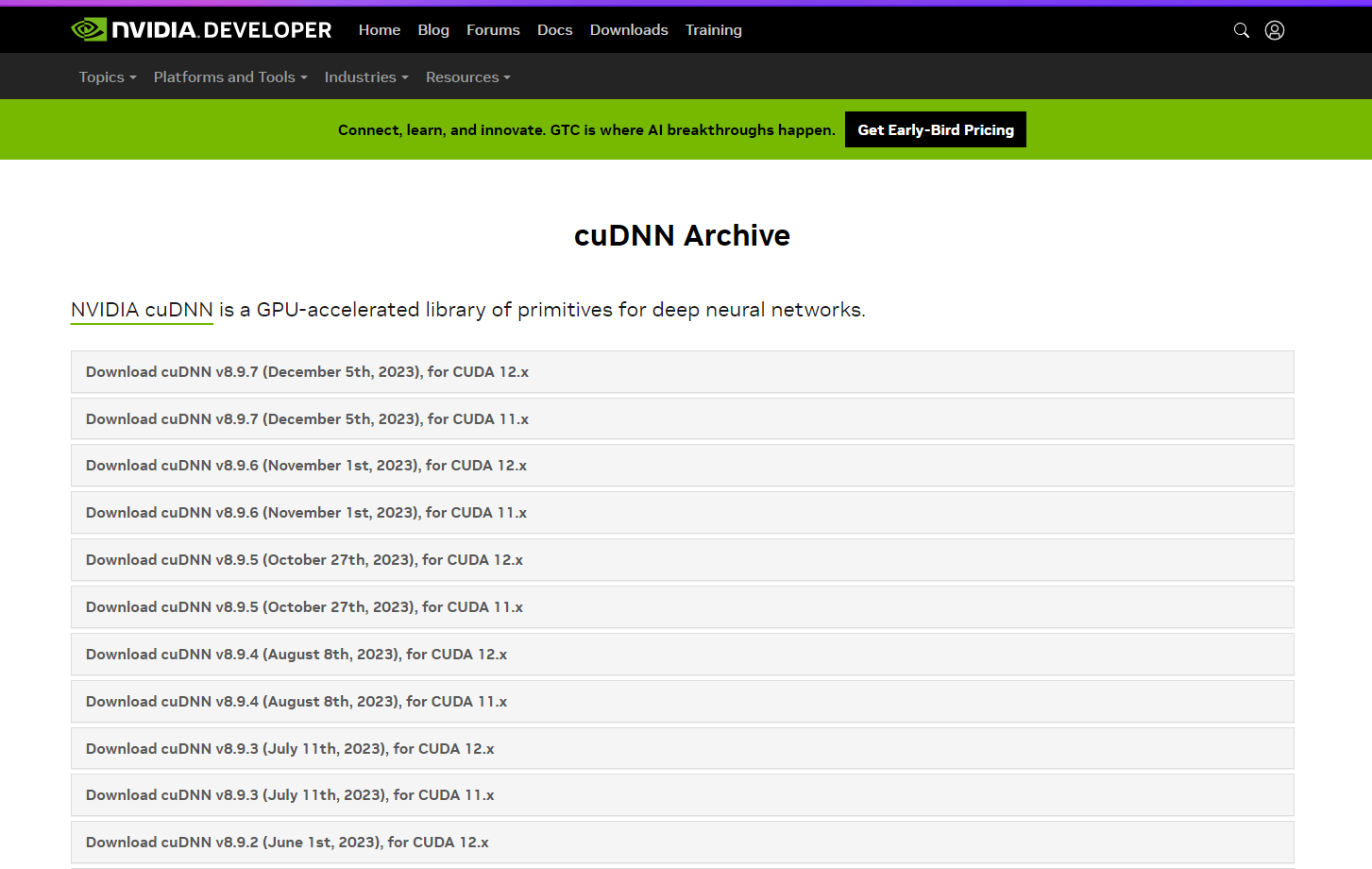
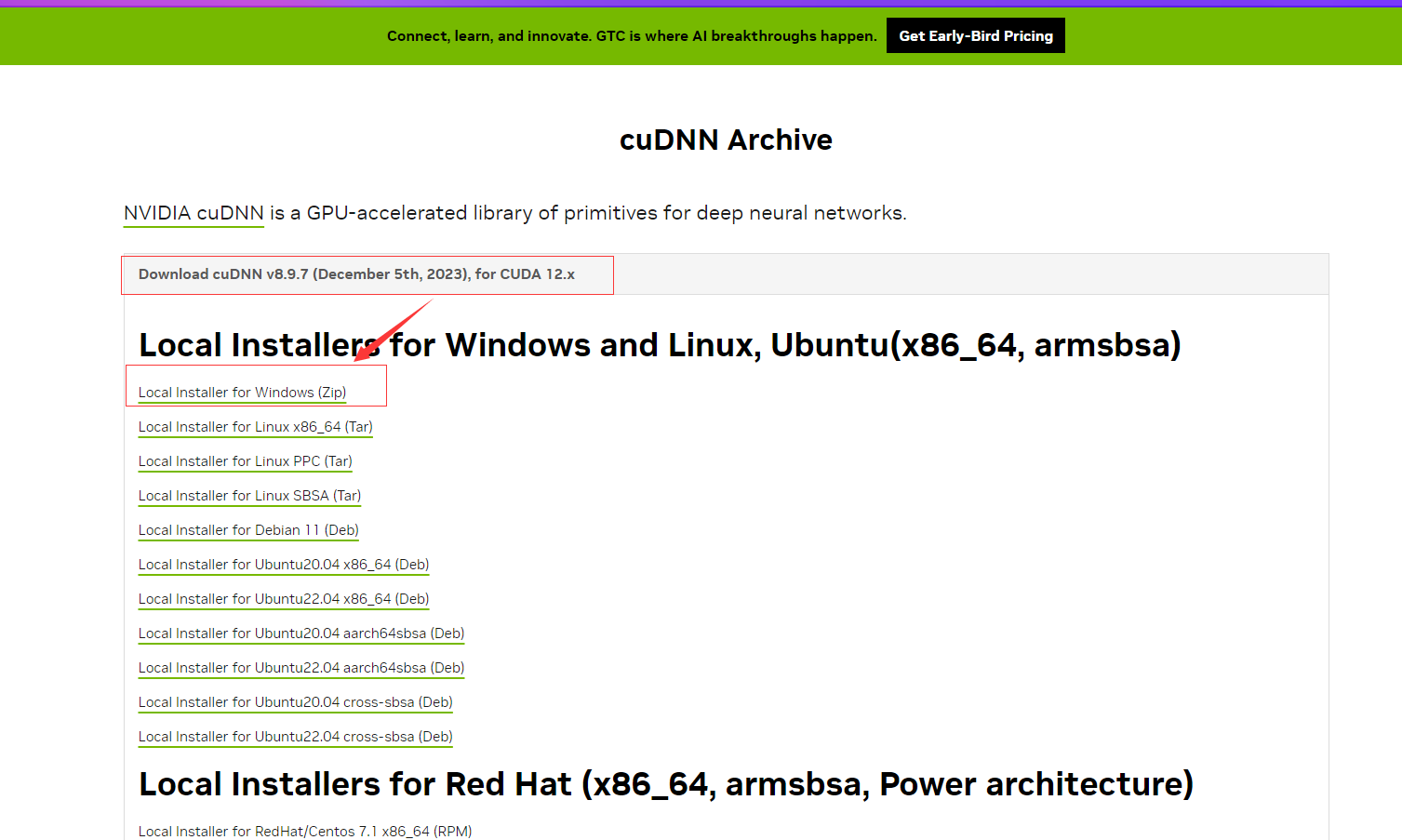
下载好用,先进行cuda的安装,*如果之前您有安装其它低版本的CUDA,在不使用的情况下可以先通过卸载程序的控制面板里先卸载。再进行安装:

OK

以上安装都说有报错,重启电脑再继续安装即可。安装完后,我们先配置环境变量。
添加CUDA的环境变量(如果已经存在,则不需要重复添加)
配置好后,解压cudnn-windows-x86_64-8.9.7.29_cuda12-archive.zip,可以看到三个文件夹
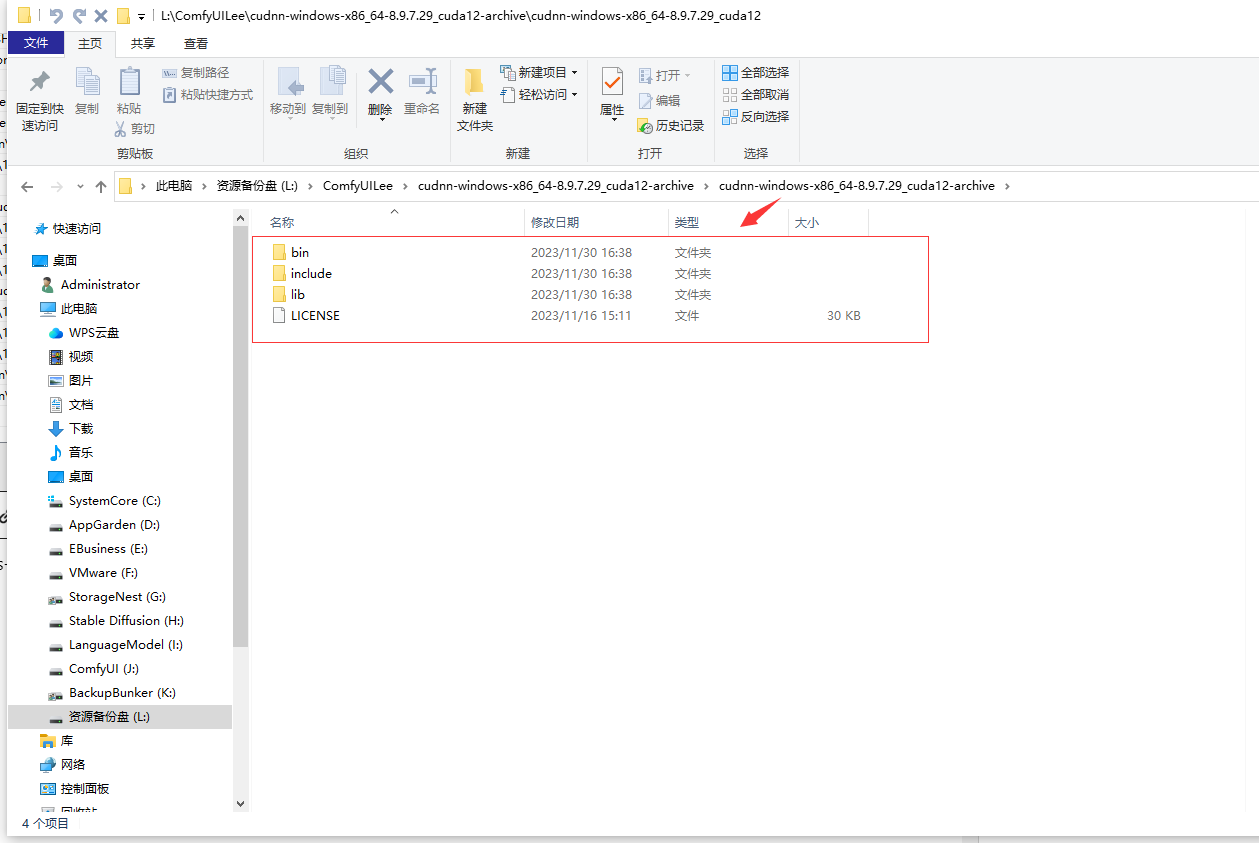
把红框圈住的地方COPY到刚刚安装好的CUDA的C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4这个文件夹内
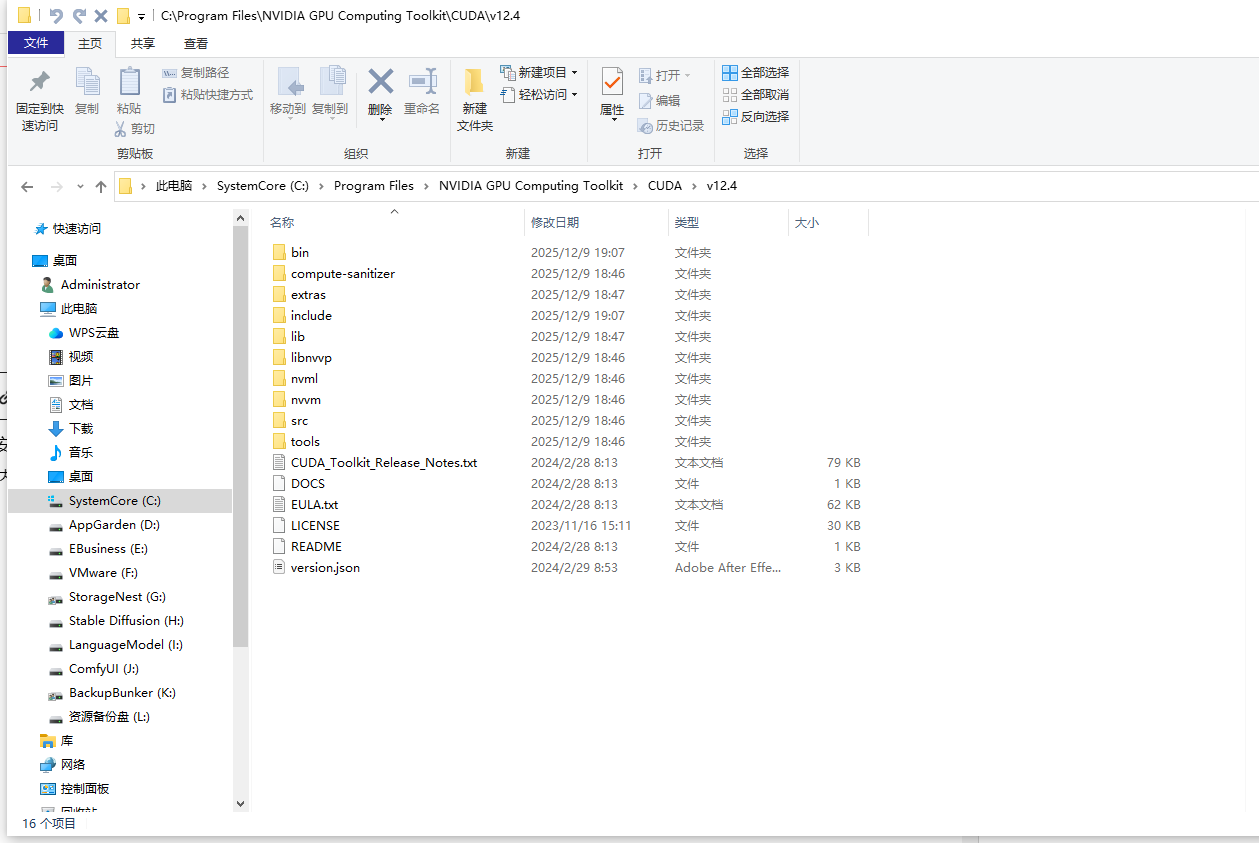
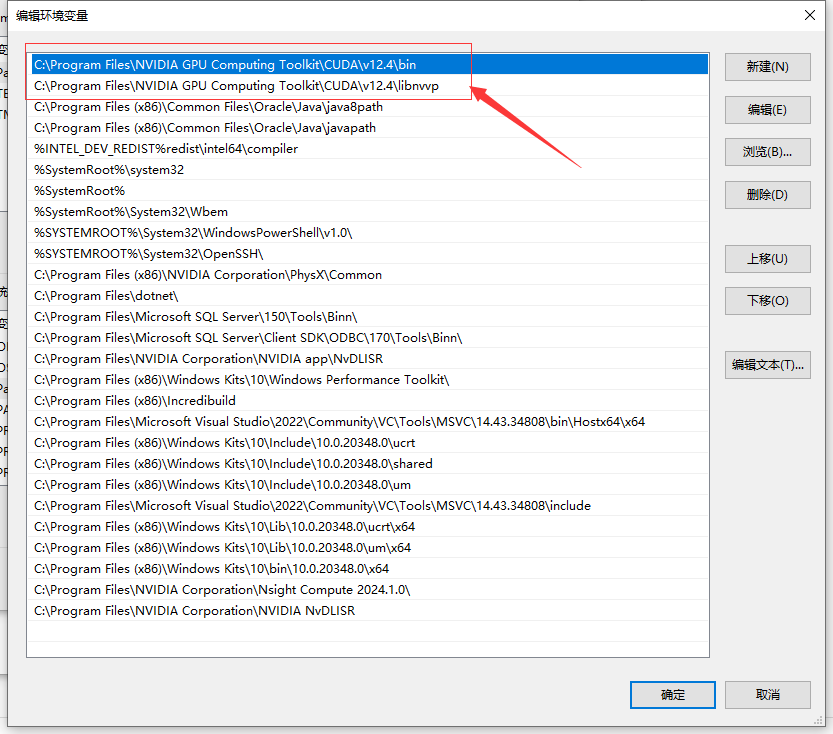
继续给cuDNN添加相应的环境变量
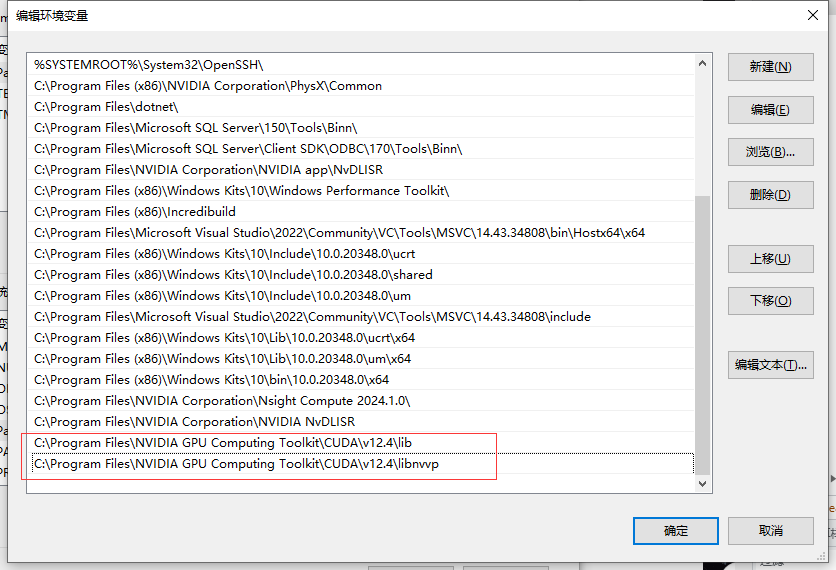
#leepoet的CUDA及cuDNN的环境变量如下:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\lib
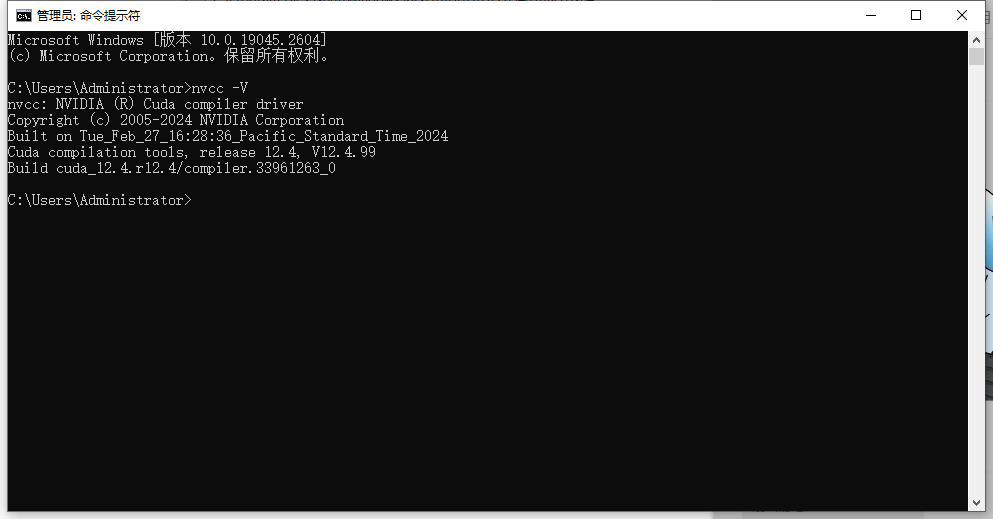
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\libnvvp配置好环境变量后,验证:nvcc -V
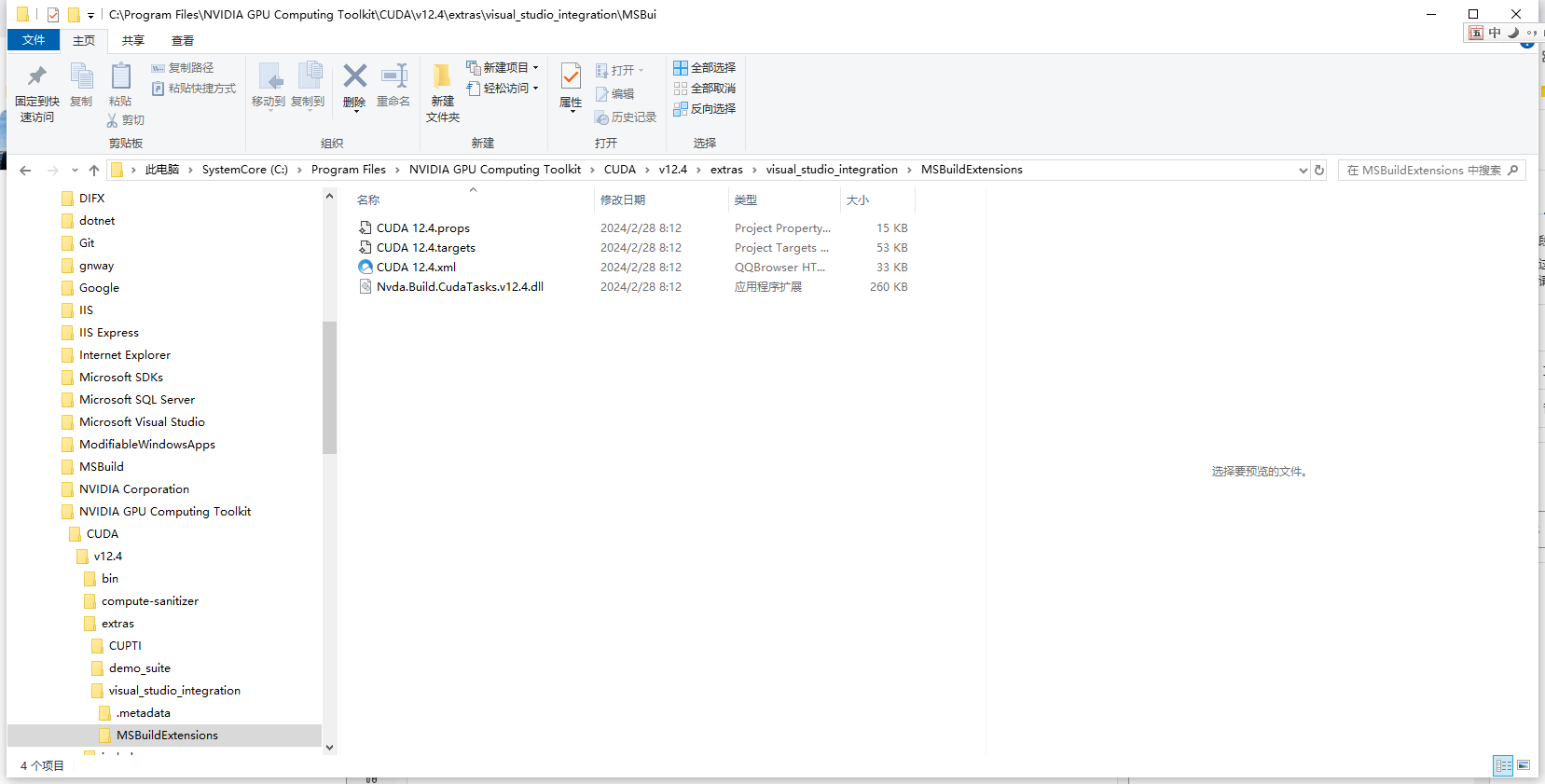
粘贴到C:\Program Files\Microsoft Visual Studio\2022\Community\MSBuild\Microsoft\VC\v170\BuildCustomizations这个目录下
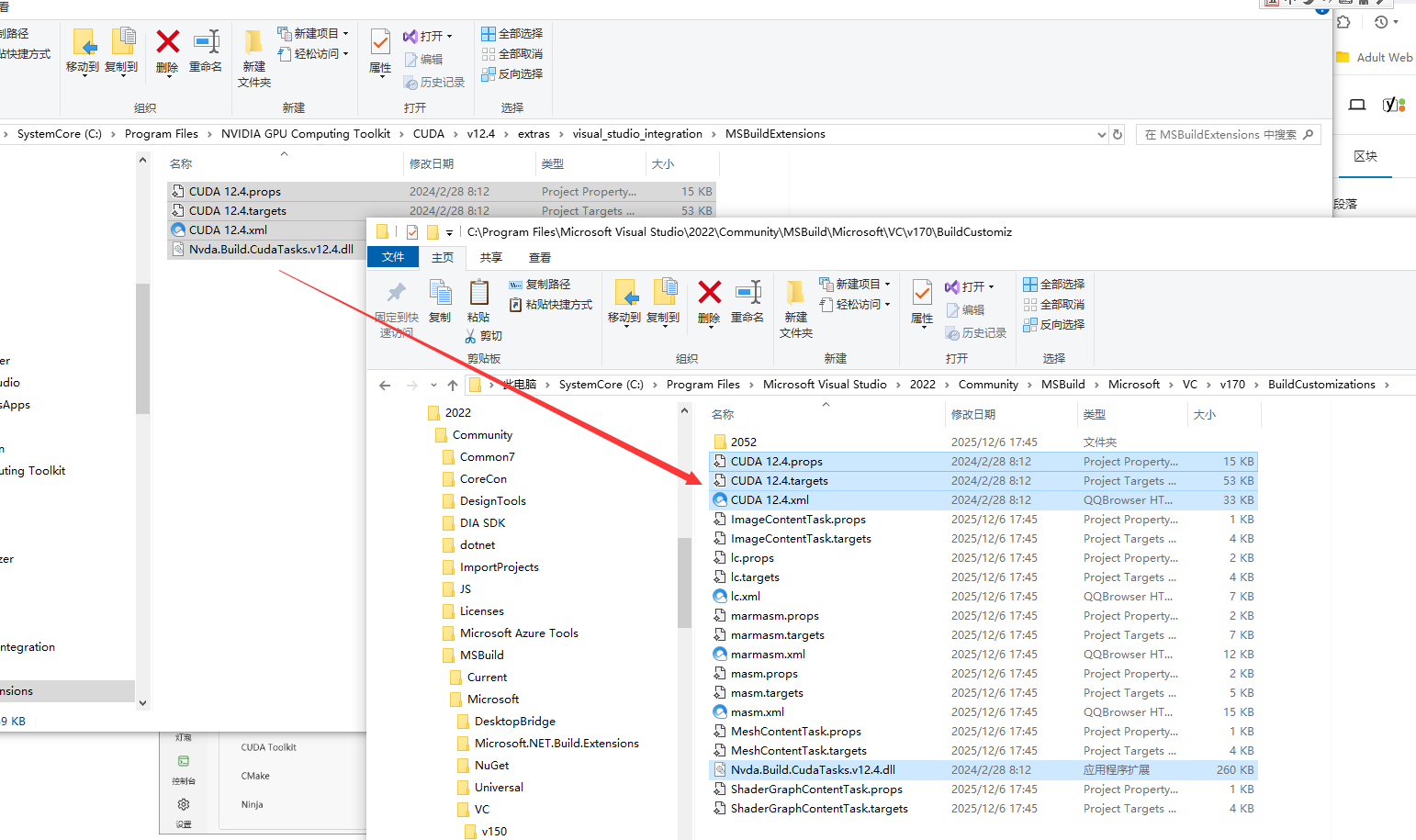
以上就算是把llama-cpp-python安装的环境配置好了。下面再通过虚拟环境构建安装llama-cpp-python。
打开启动器命令提示符,可以通过这个直接到这个整合包的虚拟环境。
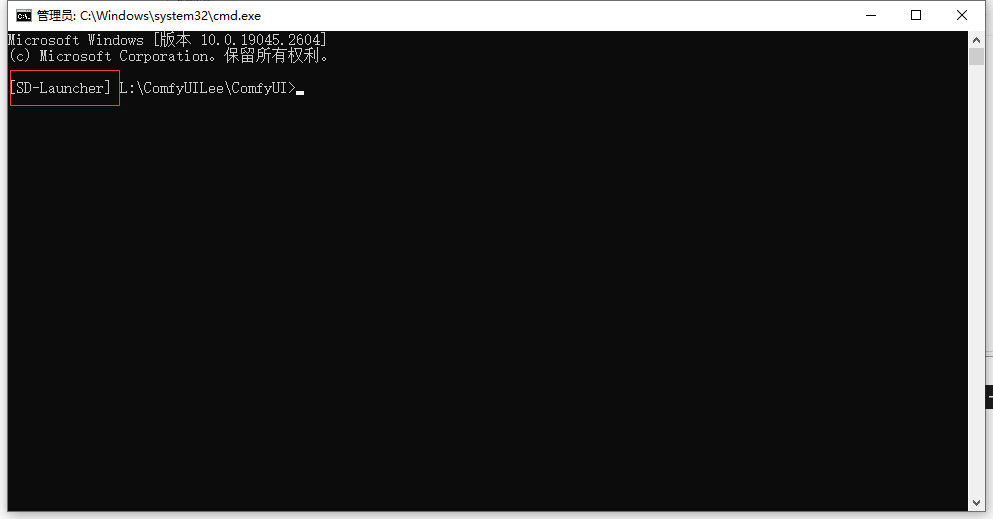
可以看到红框框住的这个标识,实际上就是这个整合包的虚拟环境的标识
set CMAKE_ARGS=-DGGML_CUDA=on
python.exe -m pip install llama-cpp-python --force-reinstall --no-cache-dir| 命令/参数 | 解释 |
|---|---|
set CMAKE_ARGS="-DGGML_CUDA=on" | 设置一个名为 CMAKE_ARGS的环境变量,其值为 -DGGML_CUDA=on。这个变量会传递给后续的编译过程,指示构建系统启用对CUDA的支持。 |
python.exe -m pip install | 使用Python模块方式运行pip进行安装,这通常比直接运行pip命令更可靠。 |
llama-cpp-python | 要安装的Python包名称,它是对C++库llama.cpp的Python封装。 |
--force-reinstall | 强制重新安装该包及其所有依赖。如果已存在安装版本,会先卸载再安装,确保是最新编译的版本。 |
--no-cache-dir | 禁用pip的缓存。这能确保pip不会使用之前下载或编译的缓存文件,而是从头开始获取源码并进行编译。 |
这条命令组合起来的效果是:强制pip忽略缓存,重新从源码编译并安装支持CUDA的llama-cpp-python库。通过pip install llama-cpp-python安装的是仅支持CPU的版本。通过从源码编译并设置CMAKE_ARGS,可以解锁GPU加速功能,在处理大语言模型时能获得数倍的速度提升。
执行命令后

先是下载库从源码编译,可能需要十几到二十分钟。
可以看到已经安装成功了。*安装后完有其它库的冲突能解决就自己解决,LeePoet是选择性忽略,主打一个能用就行。
后面就是关掉启动器,重新启动。它会自己解析并检验各种依赖。
启动完进入UI后,这次从反推到Z-image生图768x1536px的图片大概在40秒左右了。
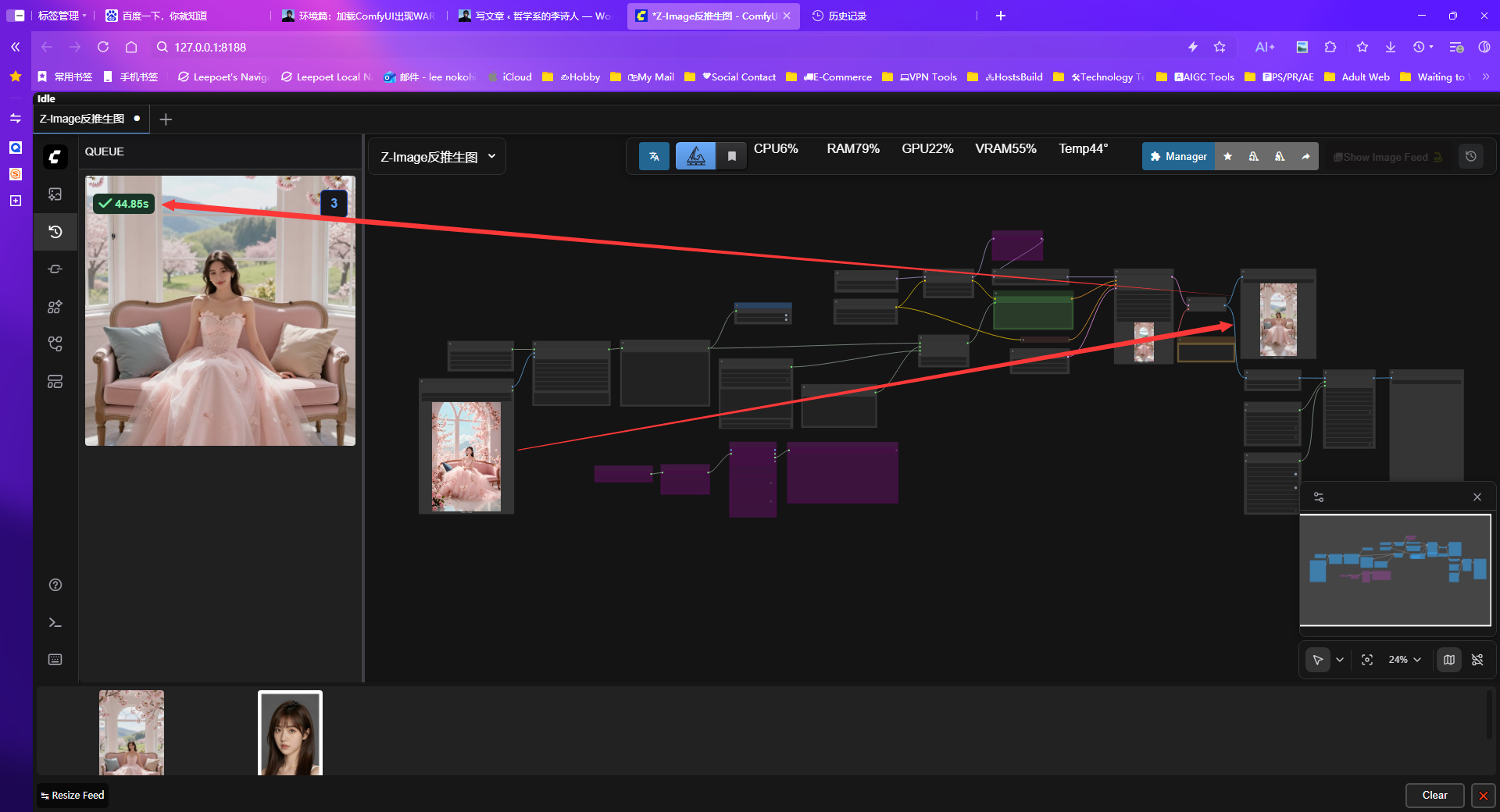
李诗人这次使用的是家用电脑配置相对一般,但是能有这个速度还是相对满意的。