告别天价软件!开源数字人项目,让你轻松打造专属虚拟分身
是否曾对炫酷的数字人技术心动,却被高昂的成本和陡峭的学习曲线劝退?无论是想成为虚拟主播,还是开发AI助手,今天这篇文章将是你的终极入门指南。我精选了5个GitHub上高星的开源项目,覆盖从人脸生成、实时驱动到智能对话的全流程,帮你零成本开启数字人创作之旅!
LeePoet Tech Note
2021年开始慢慢的零基础接触AIGC已然好长时间,期间随着很多AI大厂及各大平台的推广,后大批量的AI好爱者及专业人士涌入,新技术层出不穷,可以说这两年每天都有新技术在开源……基于深度学习开发出了如:AI绘图、ChatGPT对话、本文到语音的各种生成式模型,成倍人力的加入使得AI技术的更新日新月异,固然,吾辈唯有不断学习……
– LeePoet
是否曾对炫酷的数字人技术心动,却被高昂的成本和陡峭的学习曲线劝退?无论是想成为虚拟主播,还是开发AI助手,今天这篇文章将是你的终极入门指南。我精选了5个GitHub上高星的开源项目,覆盖从人脸生成、实时驱动到智能对话的全流程,帮你零成本开启数字人创作之旅!
AI发烧友们,大家好!最近是不是感觉哪里都在谈“智能体(Agent)”?从自动编程到智能决策,它俨然成了AI界的新晋“顶流”。但面对海量信息,你是否也曾感到无从下手:教程太浅、门槛太高,想亲手实践却找不到合适的项目?
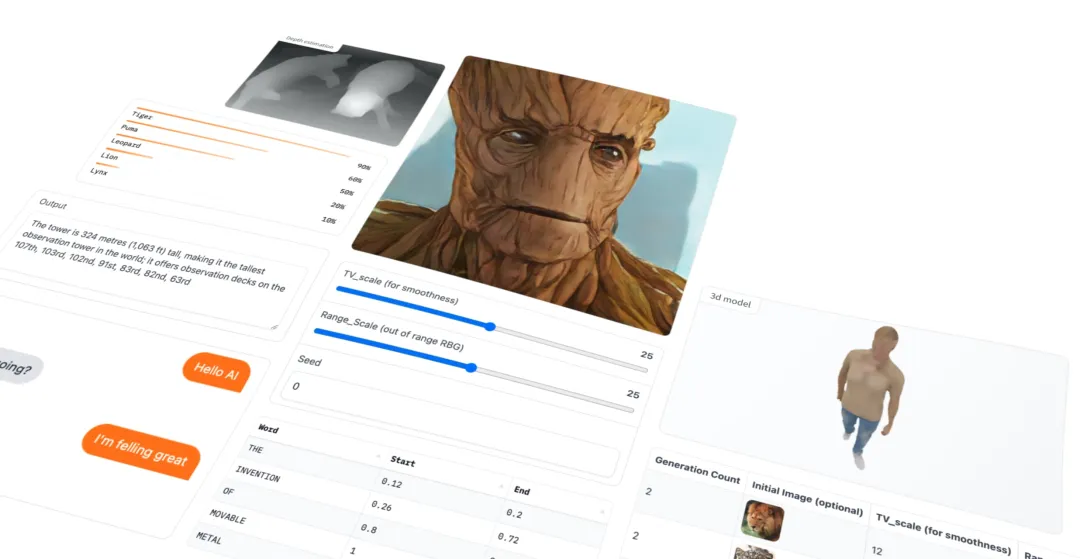
精选10个GitHub高星AI开源项目,涵盖LLaMA大模型、Stable Diffusion图像生成、Whisper语音识别、YOLOv8目标检测等核心技术。免费商用,适合开发者、研究者和技术爱好者学习与实战。包含项目地址、核心价值和最佳应用场景。
今天给大家推荐一款我最近深度体验的ComfyUI节点——ComfyUI-HYPIR,这是一个基于HYPIR项目开发的图像修复工具,专门针对SD2.1模型进行了优化,能够实现高质量的图像修复和超分辨率放大。该技术基于扩散模型生成的分数先验进行图像修复与放大,具有高质量、清晰、锐利的效果。
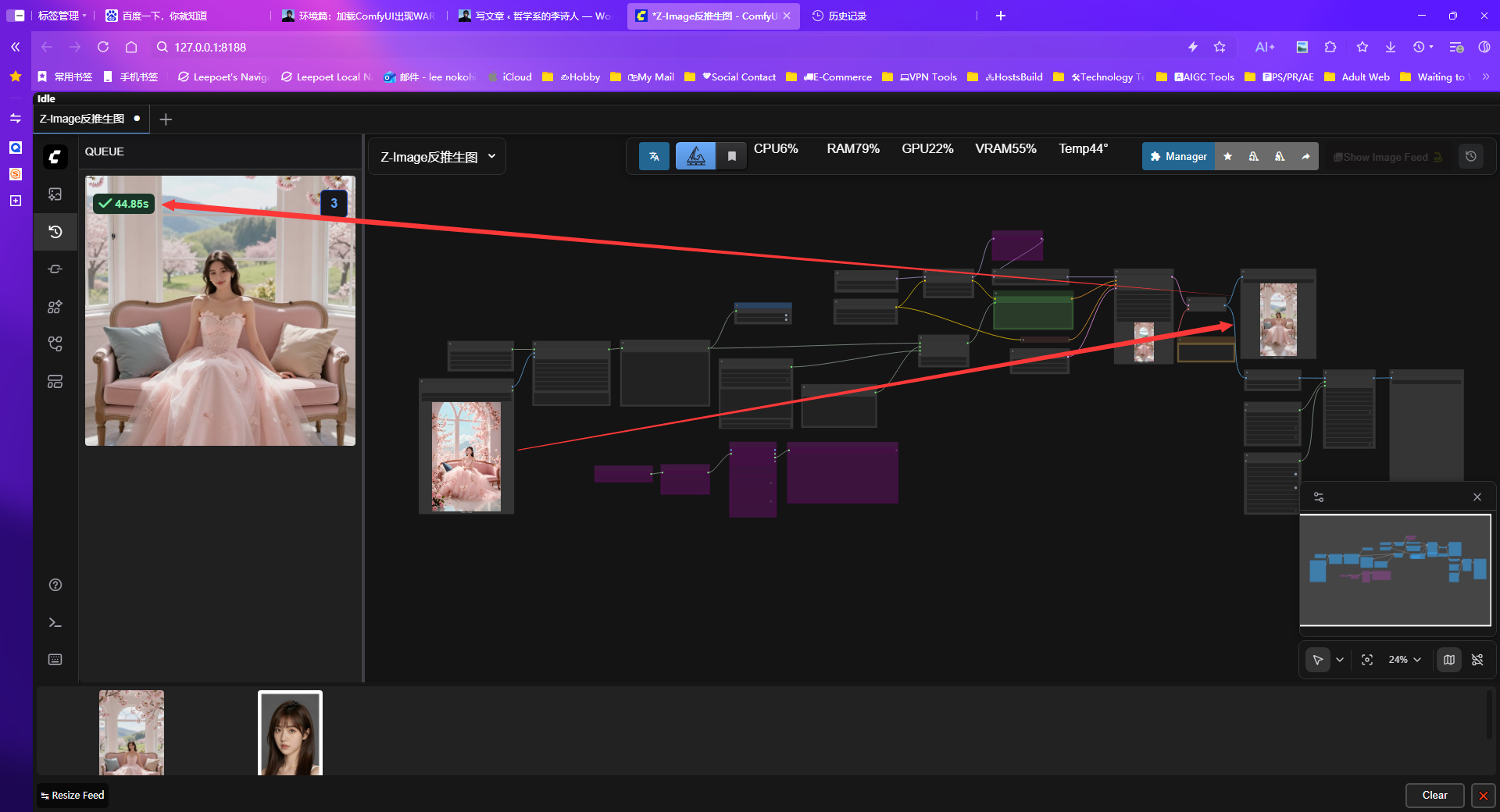
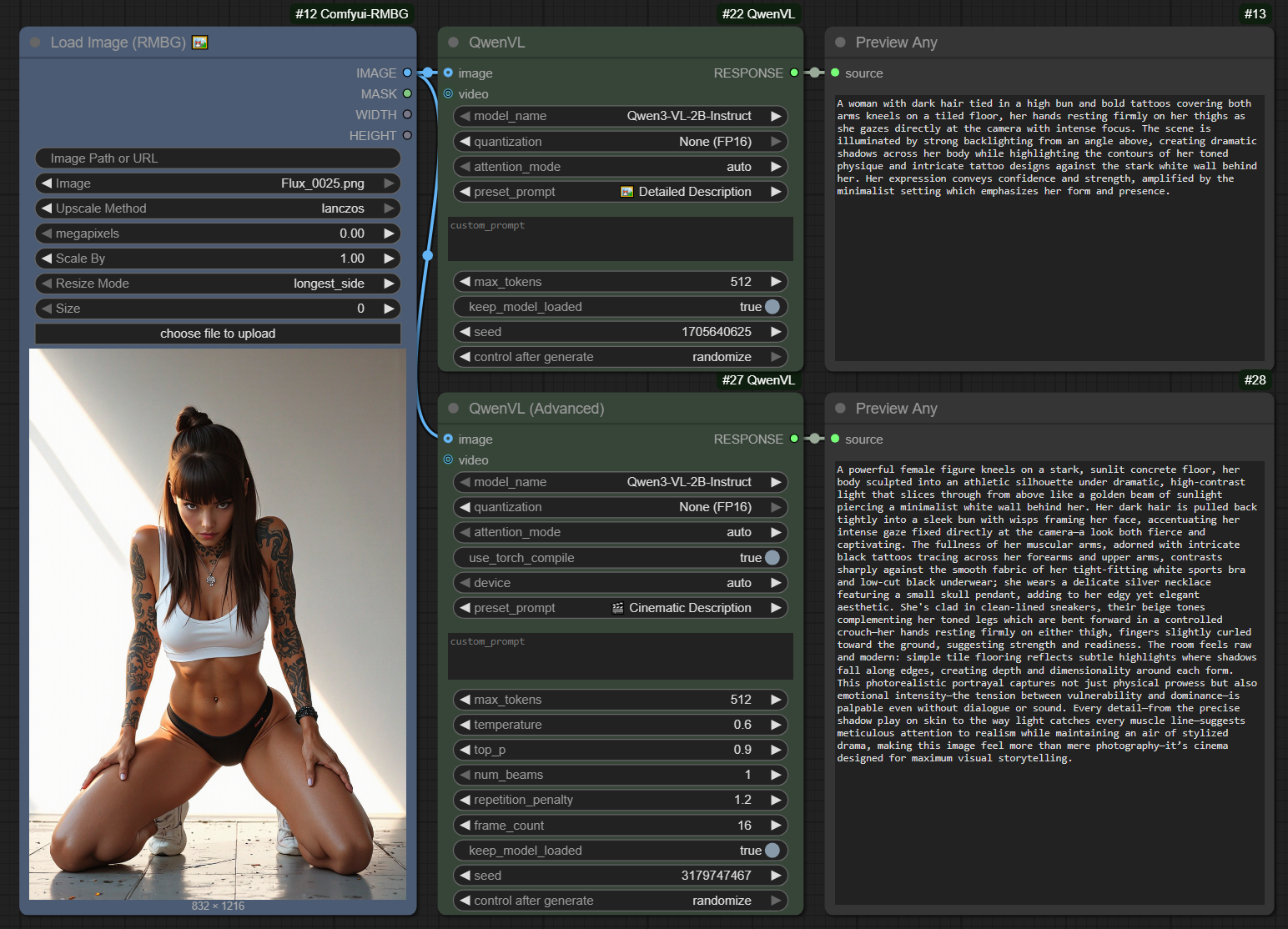
在 ComfyUI 的视觉语言处理场景中,Qwen3VL 模型凭借出色的语义对齐能力,成为图像反推提示词、智能标注及 Z-Image 洗图的常用工具,但它的推理速度却始终是一大短板 ——4060Ti 16G 显卡反推需 50 秒,3060 12G 更是要耗时 2 分钟,难以适配高频批量的洗图需求。
这个插件对于 ComfyUI 用户来说,实用性非常高,而且考虑到了不同的硬件配置需求。它直接把像 Qwen3-VL 这样领先的视觉语言模型带到了 ComfyUI 的节点式工作流中,让用户能以更直观的方式使用多模态能力,无论是图片分析还是未来的视频处理(根据介绍),都提供了强大的基础。
这是一个 ComfyUI 自定义的反推节点,它集成了阿里巴巴的 Qwen3-VL-4B-Instruct-FP8 视觉语言模型。该模型运行所需的显存较低,大约 10GB 左右。开发者提到,它适合用在图像放大的工作流程中,作为图像理解(“看懂”图片内容)的工具。
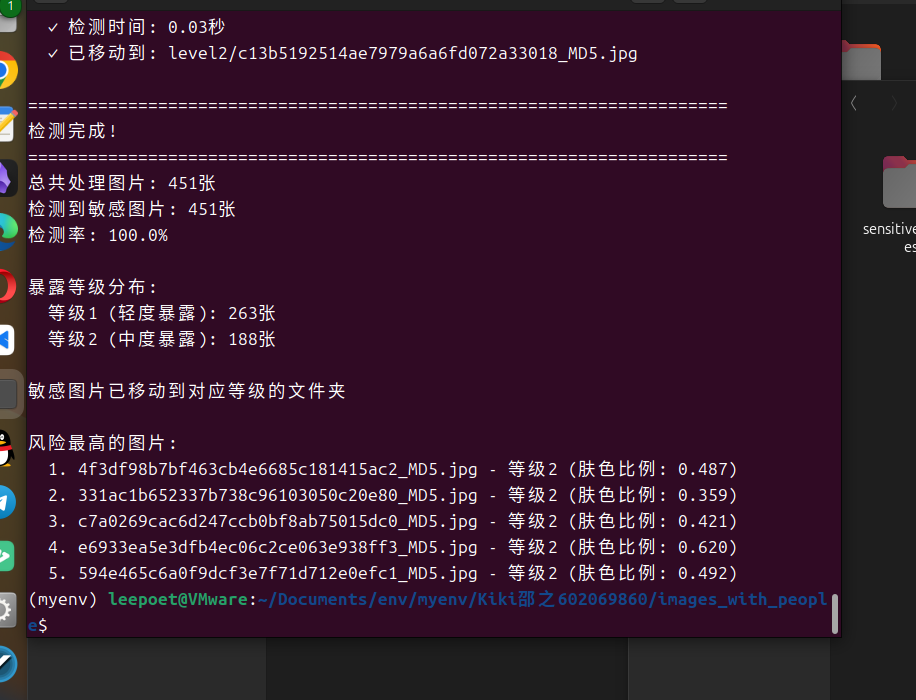
你是否也曾在数千张照片中翻找一张重要合影?是否因为图片太多而放弃整理?本文是数字时代每个人的“图片救星”。无论你是拥有上万张照片的摄影爱好者,还是被工作图片淹没的职场人,LeePoet将用AI技术为你提供从简单到专业的全系列解决方案。
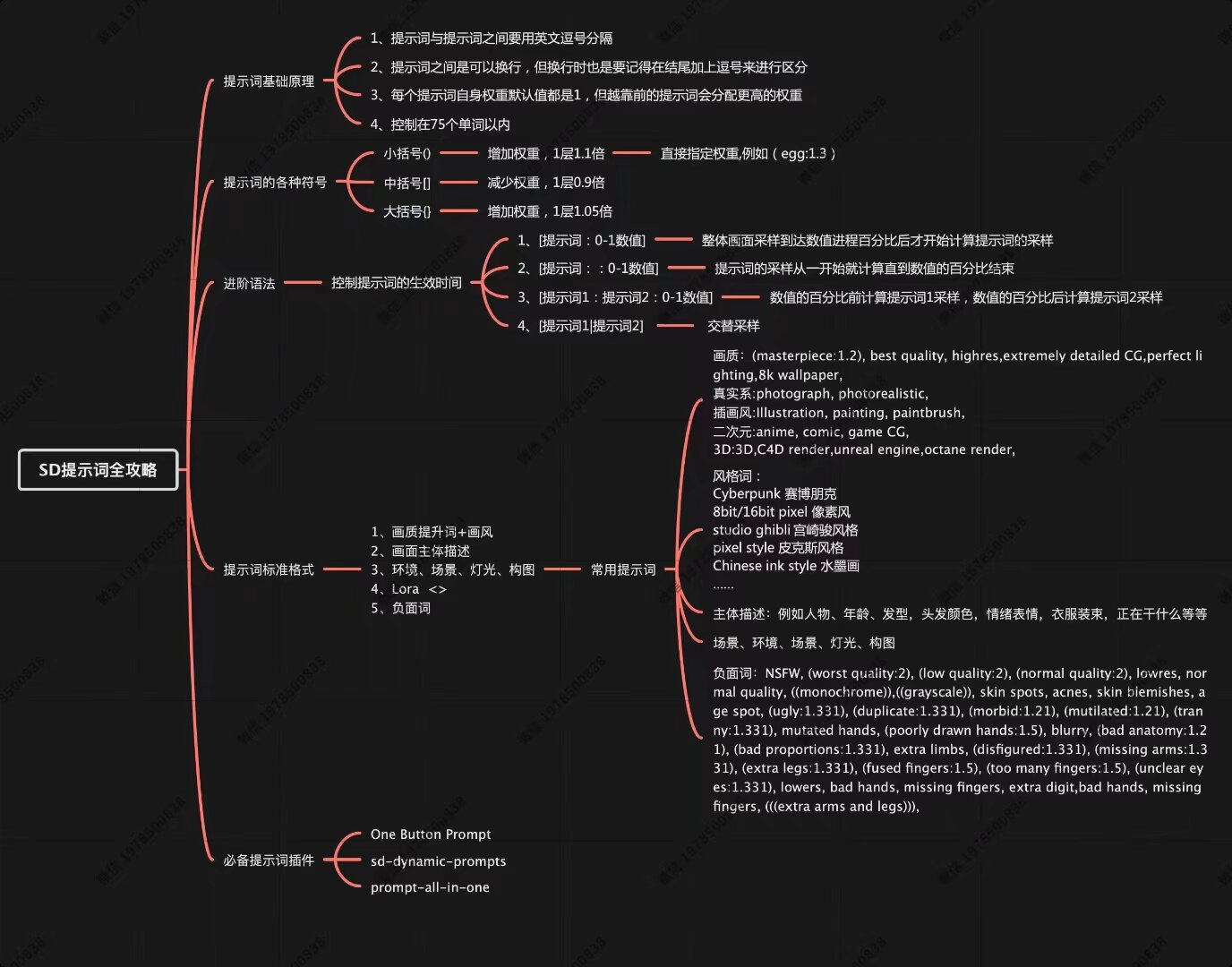
Stable Diffusion作为当前最受欢迎的AI绘画工具之一,其核心秘密就在于“提示词”的运用。本文基于详细的思维导图,为您全面解析SD提示词的使用技巧,帮助您精准实现创作意图。提示词是用户与Stable Diffusion模型之间起着“契约”的作用。通过精确的描述与灵活的控制方式,它们能够将抽象的概念转化为具体的图像;同时还能在保证生成结果多样性的同时,确保这些结果的可控性。
老照片翻新,或者是不清楚的图想变清晰,或者清晰的小图想变成高清大图,这是我们很多人都有的需求,但怎么做?以前可能比较麻烦,但现在有Stable-Diffusion后,一切变的简单。