ComfyUI-HYPIR节点:LeePoet力推基于SD2.1图像超清修复放大
今天给大家推荐一款我最近深度体验的ComfyUI节点——ComfyUI-HYPIR,这是一个基于HYPIR项目开发的图像修复工具,专门针对SD2.1模型进行了优化,能够实现高质量的图像修复和超分辨率放大。该技术基于扩散模型生成的分数先验进行图像修复与放大,具有高质量、清晰、锐利的效果。
LeePoet Tech Note
Stable Diffusion 是一种开源的文本到图像生成模型,旨在根据用户提供的文本描述生成高质量的图像。这种模型通过逐步添加噪声到图像中,然后通过学习反向过程来生成新的图像。模型能够根据文本提示生成图像,这种能力使其在艺术创作、概念设计等领域非常受欢迎。
今天给大家推荐一款我最近深度体验的ComfyUI节点——ComfyUI-HYPIR,这是一个基于HYPIR项目开发的图像修复工具,专门针对SD2.1模型进行了优化,能够实现高质量的图像修复和超分辨率放大。该技术基于扩散模型生成的分数先验进行图像修复与放大,具有高质量、清晰、锐利的效果。
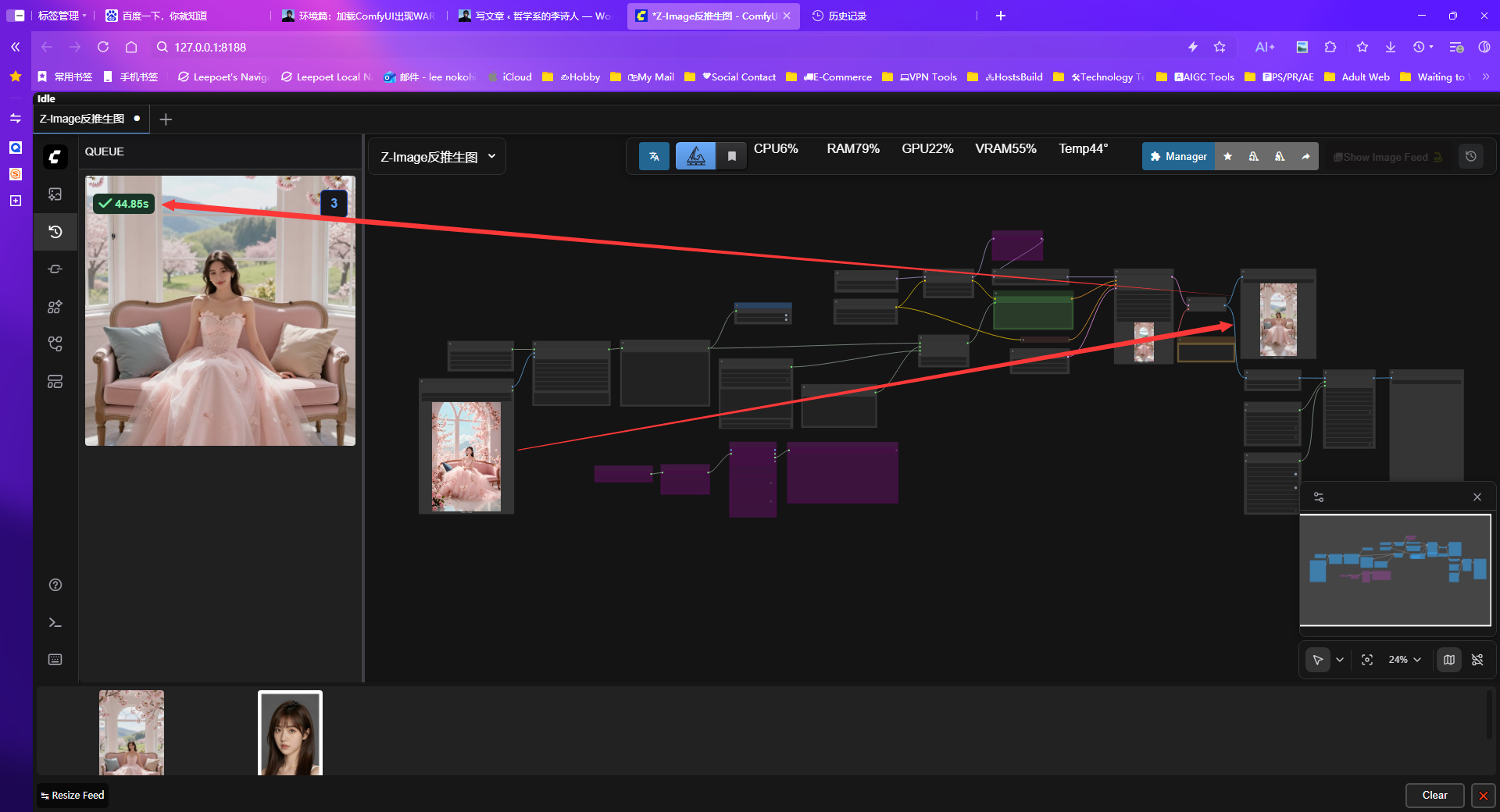
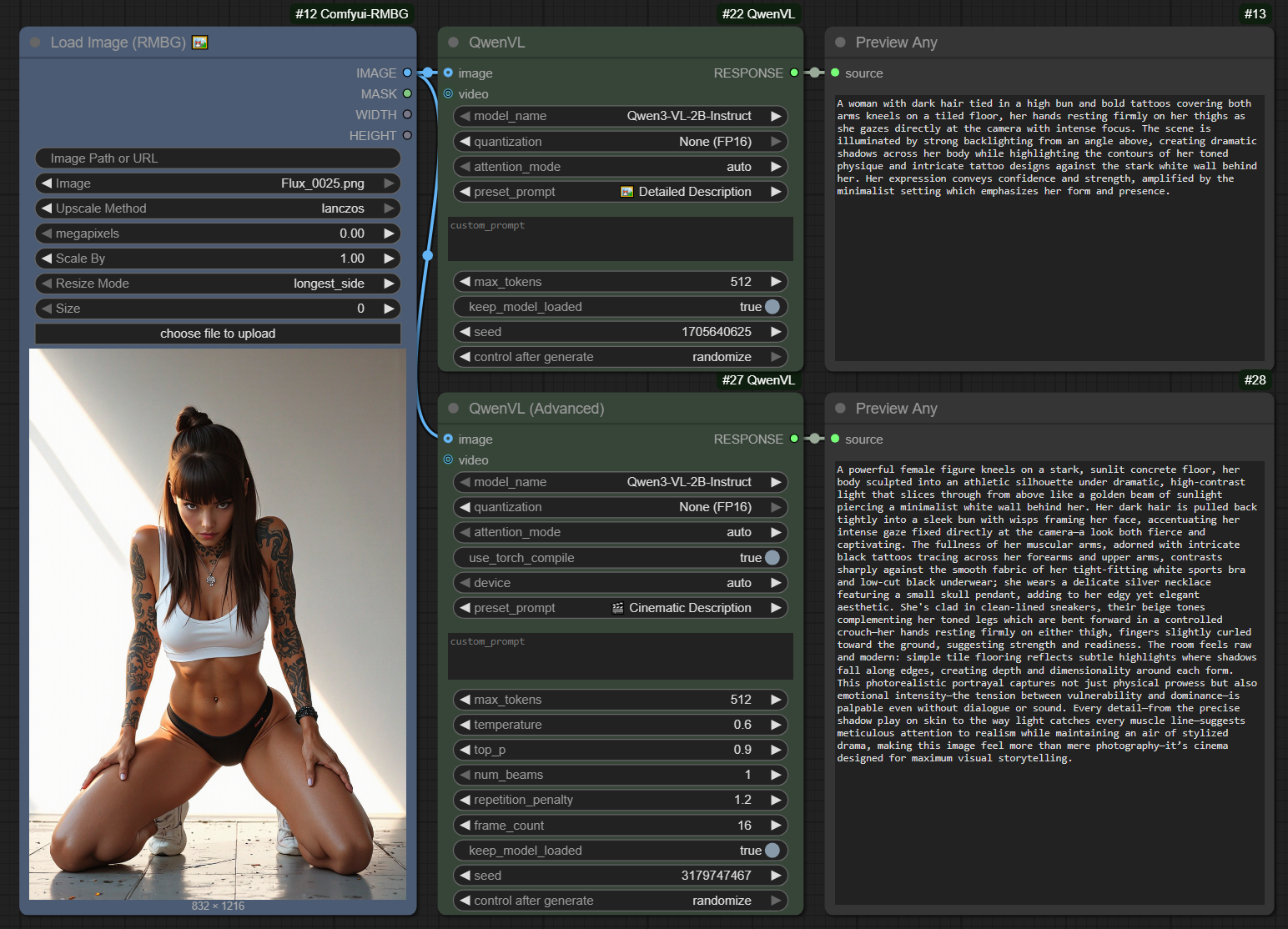
在 ComfyUI 的视觉语言处理场景中,Qwen3VL 模型凭借出色的语义对齐能力,成为图像反推提示词、智能标注及 Z-Image 洗图的常用工具,但它的推理速度却始终是一大短板 ——4060Ti 16G 显卡反推需 50 秒,3060 12G 更是要耗时 2 分钟,难以适配高频批量的洗图需求。
这个插件对于 ComfyUI 用户来说,实用性非常高,而且考虑到了不同的硬件配置需求。它直接把像 Qwen3-VL 这样领先的视觉语言模型带到了 ComfyUI 的节点式工作流中,让用户能以更直观的方式使用多模态能力,无论是图片分析还是未来的视频处理(根据介绍),都提供了强大的基础。
这是一个 ComfyUI 自定义的反推节点,它集成了阿里巴巴的 Qwen3-VL-4B-Instruct-FP8 视觉语言模型。该模型运行所需的显存较低,大约 10GB 左右。开发者提到,它适合用在图像放大的工作流程中,作为图像理解(“看懂”图片内容)的工具。
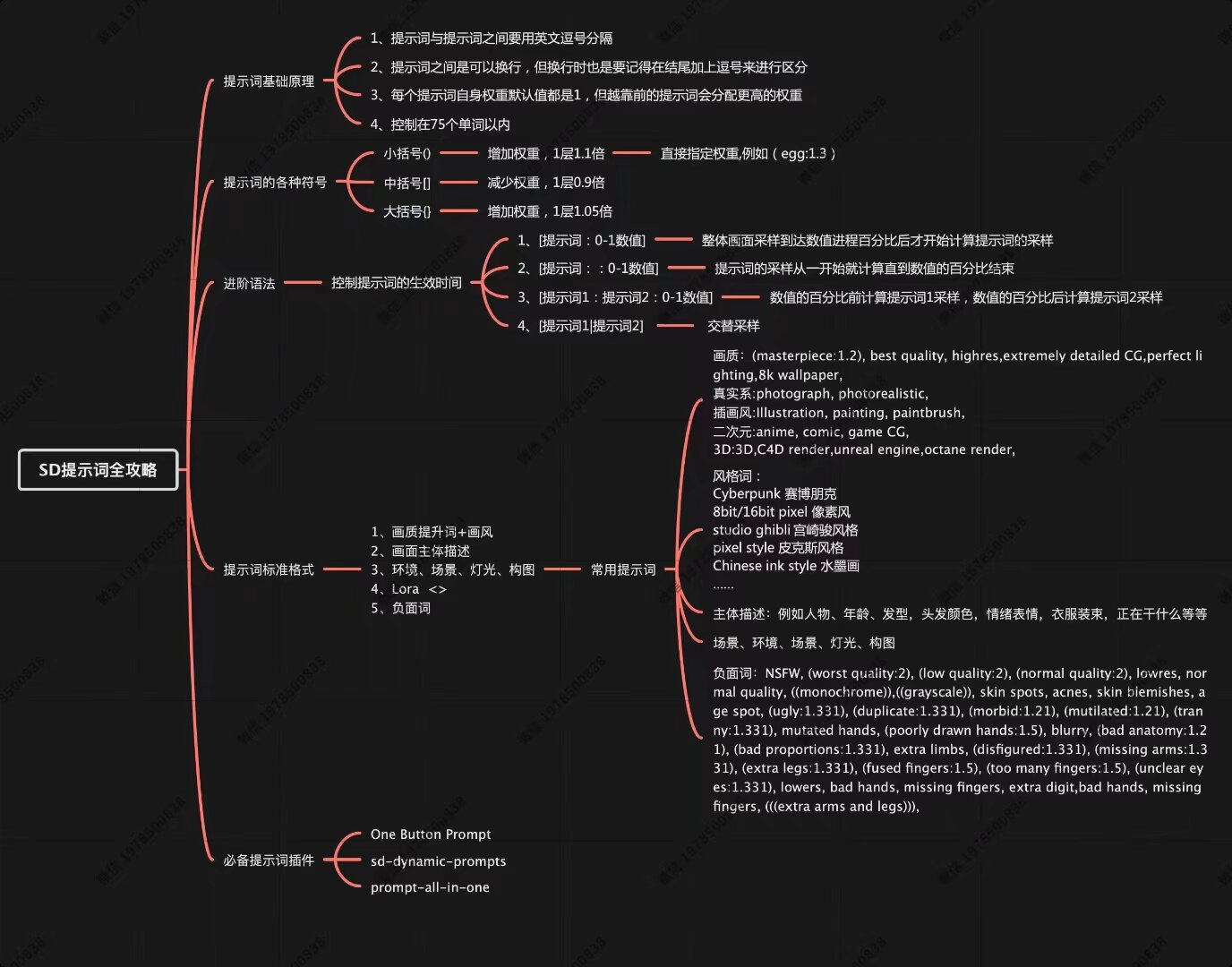
Stable Diffusion作为当前最受欢迎的AI绘画工具之一,其核心秘密就在于“提示词”的运用。本文基于详细的思维导图,为您全面解析SD提示词的使用技巧,帮助您精准实现创作意图。提示词是用户与Stable Diffusion模型之间起着“契约”的作用。通过精确的描述与灵活的控制方式,它们能够将抽象的概念转化为具体的图像;同时还能在保证生成结果多样性的同时,确保这些结果的可控性。
老照片翻新,或者是不清楚的图想变清晰,或者清晰的小图想变成高清大图,这是我们很多人都有的需求,但怎么做?以前可能比较麻烦,但现在有Stable-Diffusion后,一切变的简单。
LoRA并非一种完整的模型重训练技术,而是一种高效的参数微调。简单来讲,就是借用一个预训练好的大型基础模型进行微调以适应新任务时,无需调动模型全部的数十亿个参数。
黑森林的Kontext 模型已经开源了一段时间,社区生态迅猛发展,Kontext LoRA已经层出不穷。就在今天,魔搭社区的开发者开源了4种全新的Kontext LoRA,blingbling的雕像风格、拿捏氛围感的图像美学提升神器
提示词是用户与Stable Diffusion模型之间的“契约”,通过精准描述与灵活控制,实现从抽象创意到具体图像的转化,同时平衡生成结果的多样性与可控性。
Nunchaku Qwen-Edit 2509 是阿里巴巴通义千问团队开发的AI图像编辑模型,基于 Qwen-Image-Edit-2509 架构,并通过 Nunchaku 技术优化,显著提升了推理速度和低显存适配性。