ComfyUI-GGUF-VLM 结合 llama.cpp GPU 加速:实现图像反推秒级效率
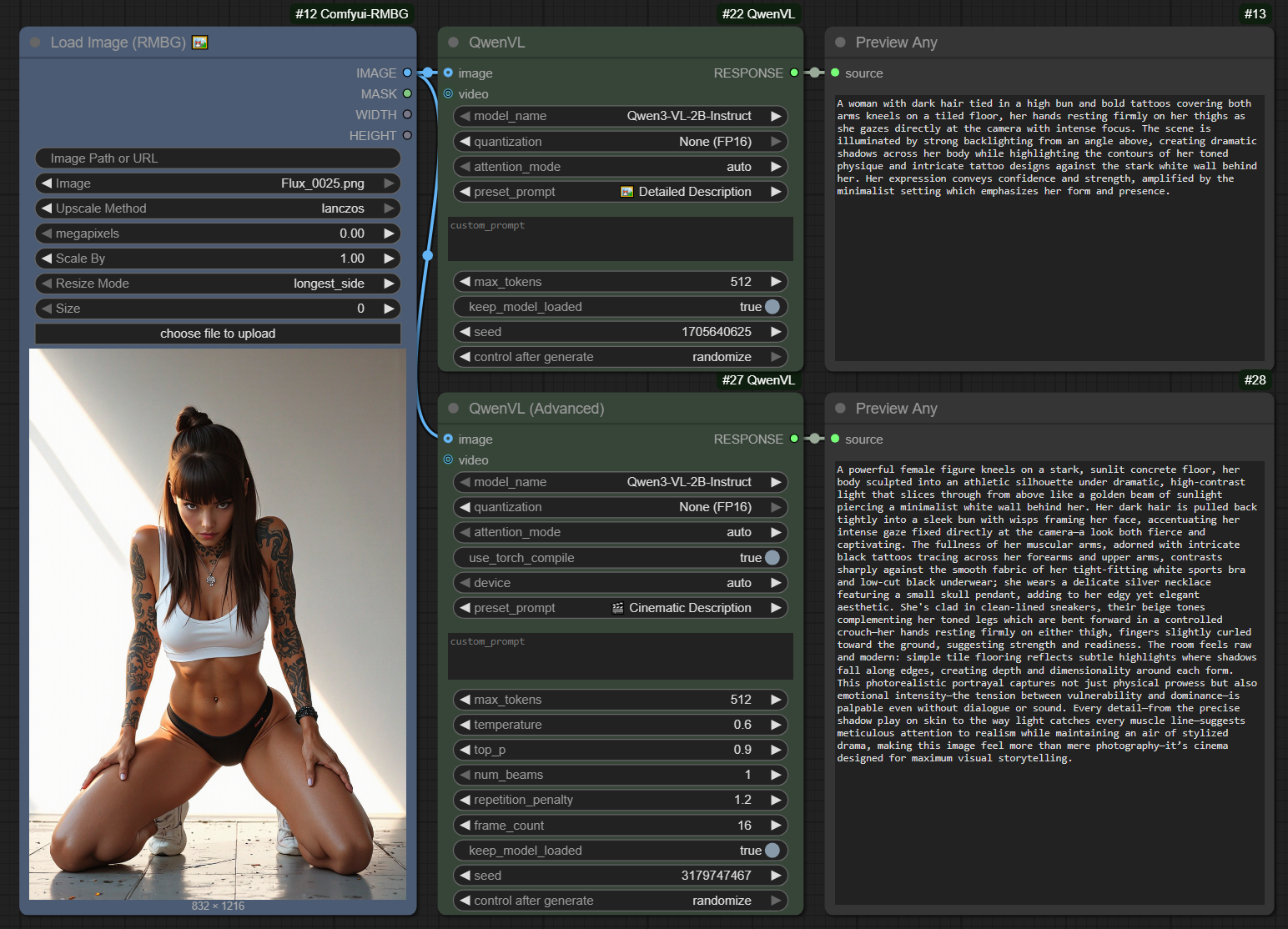
在 ComfyUI 的视觉语言处理场景中,Qwen3VL 模型凭借出色的语义对齐能力,成为图像反推提示词、智能标注及 Z-Image 洗图的常用工具,但它的推理速度却始终是一大短板 ——4060Ti 16G 显卡反推需 50 秒,3060 12G 更是要耗时 2 分钟,难以适配高频批量的洗图需求。
LeePoet Tech Note
在 ComfyUI 的视觉语言处理场景中,Qwen3VL 模型凭借出色的语义对齐能力,成为图像反推提示词、智能标注及 Z-Image 洗图的常用工具,但它的推理速度却始终是一大短板 ——4060Ti 16G 显卡反推需 50 秒,3060 12G 更是要耗时 2 分钟,难以适配高频批量的洗图需求。
这个插件对于 ComfyUI 用户来说,实用性非常高,而且考虑到了不同的硬件配置需求。它直接把像 Qwen3-VL 这样领先的视觉语言模型带到了 ComfyUI 的节点式工作流中,让用户能以更直观的方式使用多模态能力,无论是图片分析还是未来的视频处理(根据介绍),都提供了强大的基础。
这是一个 ComfyUI 自定义的反推节点,它集成了阿里巴巴的 Qwen3-VL-4B-Instruct-FP8 视觉语言模型。该模型运行所需的显存较低,大约 10GB 左右。开发者提到,它适合用在图像放大的工作流程中,作为图像理解(“看懂”图片内容)的工具。